Llibre resum dels continguts bàsics del lliurament 4.
| Sitio: | Cursos IOC - Batxillerat |
| Curso: | Matemàtiques I (Bloc 2) ~ gener 2020 |
| Libro: | Llibre resum dels continguts bàsics del lliurament 4. |
| Imprimido por: | Guest user |
| Día: | domingo, 19 de mayo de 2024, 11:33 |
Descripción
cc
Estadística descriptiva unidimensional
En aquest primer capítol del llibre, es recorden els principals conceptes de l'estadística unidimensional (és a dir, en la què s'estudia només una variable), per a poder posteriorment encarar l'estadística de dues variables o bidimensional. Si aquests conceptes ja els domines, pots passar directament al capítol 2.Què és l'estadística?
Avui dia difícilment podem llegir un diari o veure un telenotícies sense trobar-nos gràfics i estudis estadístics. És important conèixer els conceptes bàsics d'aquesta ciència per entendre i interpretar
críticament la informació que se'ns dóna.

L'estadística és una branca de les matemàtiques que té per objectiu recopilar, organitzar, analitzar i interpretar dades referides a un col·lectiu.
Primers conceptes
Convé conèixer el vocabulari específic que es fa servir en els estudis estadístics.Població: conjunt d'individus amb algunes característiques comunes sobre el què recau l'estudi. Mostra: subconjunt de la població sobre la què es fa l'estudi quan és impossible fer l'estudi exhaustiu sobre tota la població. La mostra cal que sigui representativa de tota la població, per tal que se'n puguin extraure resultats fiables.Quan més gran sigui la mostra, més fiable seran els resultats.
Variable estadística: és la propietat o característica de la població que estem interessats a estudiar. Es solen representar per lletres majúscules X, Y, Z...Hi ha molts tipus de variables i convé començar classificant-les segons diferents criteris.
Les dades són els valors concrets que pren aquesta variable estadística.
Exemple
Si fem un estudi sobre el nombre de germans que tenen els estudiants de Batxillerat a l'IOC, podríem passar una enquesta demanant quants germans té cada estudiant.
La població estaria formada per tots els estudiants de Batxillerat de l'IOC.
La variable en aquest cas seria el nombre de germans que té cada estudiant.
I les dades serien els resultats concrets: 0 germans, 1 germà, 2 germans, etc que respongués cada estudiant a la consulta.
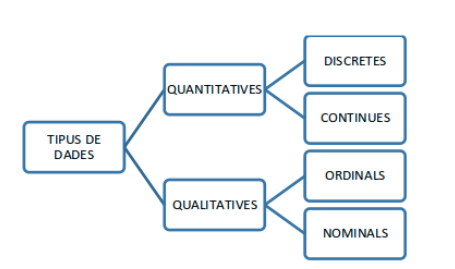
Classificació de les dades
Si les classifiquem segons si les dades es poden o no comptar parlarem de variables estadístiques quantitatives i qualitatives.
- Les variables qualitatives prenen valors no numèrics, que no es poden mesurar. Dins d'aquest tipus encara podem separar les variables ordinals tals que tot i no ser numèriques podrien ser ordenades (per exemple molt, bastant, suficientment,
poc, gens) i les nominals que són atributs que no poden ser ordenats (colors, nacionalitats, etc)
- Les variables quantitatives prenen valors numèrics, les podem mesurar. Entre elles, distingim dos tipus: discretes i contínues.
- Les variables quantitatives discretes no poden prendre valors intermedis entre dos valors possibles consecutius.
- Les variables quantitatives contínues poden prendre valors intermedis entre dos valors tan propers com vulguem.
Exemples
- Sigui X la variable estadística que estudia el color del cotxe dels ciutadans d'una certa població. Aquesta variable pot prendre els valors
X={blanc, vermell, blau, verd, groc, negre,...} i és una variable qualitativa.
- Sigui Y
la variable estadística que estudia la llargada de les erugues de les
diferents espècies de papallones d'un determinat continent. Aquesta
variable pot prendre qualsevol nombre real que està dins l'interval
[0'5, 10] cm.
- Sigui Z la variable estadística que estudia el nombre de vegades que van al cinema mensualment els habitants d'una ciutat. Aquesta variable pot prendre els valors
Z={0, 1, 2, 3, 4, ....} i és una variable quantitativa discreta, observeu que entre 1 i 2 la variable no pot prendre els valors decimals intermedis, perquè no podem anar al cinema 1,3 vegades.
La classificació anterior la podem resumir en aquest quadre:
Es recomana consultar el document Conceptes bàsics d'estadística unidimensional (pag 1-2) on trobareu exemples i explicacions més detallades d'aquests primers conceptes.
Les taules
Tal com hem dit en un inici, en estudi estadístic comença recollint un conjunt molt gran de dades de diferents maneres: amb enquestes, amb l'observació directa, etc.
Un cop recollides les dades caldrà passar-les a net, és a dir organitzar-les, de manera que siguin de fàcil interpretació, per això es posen en una taula amb diverses columnes.
Aquestes taules les anomenem taules de freqüències. Aquí indiquem quins són els conceptes que habitualment es recullen a les taules i les seves notacions, tot i que cal tenir en compte que de vegades segons el llibre o l'estudi les notacions poden variar.
N= nombre total de dades recollides (o d'individus estudiats). És possible que algun llibre posi n en lloc de N, però segur que pel context ho veuràs.
| nom | notació | definició i càlcul |
| valor de la dada
|
xi | dada que ocupa el lloc i |
| freqüència absoluta | ni | indica el nombre de vegades que s'ha observat la dada xi |
| freqüència relativa | fi |  freqüència absoluta dividida pel nombre total de dades freqüència absoluta dividida pel nombre total de dades |
| percentatge | fi% | format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%2219.5%22%20y1%3D%2225.5%22%20y2%3D%2225.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%228.5%22%20y%3D%2215%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2220%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2242%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1cedebb6e872f539bef8c3f9198%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%2231%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2231%22%3E100%3C%2Ftext%3E%3C%2Fsvg%3E) freqüència relativa en tant per cent freqüència relativa en tant per cent |
| freq. absoluta acumulada | Ni | Ni=n1+n2+...+ni nombre de dades inferiors o iguals a xi |
| freq. relativa acumulada | Fi | format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math19c64e078412cbccf2619bcc992'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAAA52hlYWQQC2qxAAACfAAAADZoaGVhCGsXSAAAArQAAAAkaG10eE2rRkcAAALYAAAADGxvY2EAHTwYAAAC5AAAABBtYXhwBT0FPgAAAvQAAAAgbmFtZaBxlY4AAAMUAAABn3Bvc3QB9wD6AAAEtAAAACBwcmVwa1uragAABNQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACsALv%2F%2FAAAAKwAu%2F%2F%2F%2F1v%2FUAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAEAgABVAtUCqwALAEkBGLIMAQEUExCxAAP2sQEE9bAKPLEDBfWwCDyxBQT1sAY8sQ0D5gCxAAATELEBBuSxAQETELAFPLEDBOWxCwX1sAc8sQkE5TEwEyERMxEhFSERIxEhgAEAVQEA%2FwBV%2FwABqwEA%2FwBW%2FwABAAABACAAAACgAIAAAwAvGAGwBBCwA9SwAxCwAtSwAxCwADywAhCwATwAsAQQsAPUsAMQsAI8sAAQsAE8MDE3MxUjIICAgIAAAAEAAAABAADVeM5BXw889QADBAD%2F%2F%2F%2F%2F1joTc%2F%2F%2F%2F%2F%2FWOhNzAAD%2FIASAA6sAAAAKAAIAAQAAAAAAAQAAA%2Bj%2FagAAF3AAAP%2B2BIAAAQAAAAAAAAAAAAAAAAAAAAMDUgBVA1YAgADIACAAAAAAAAAAKAAAAKEAAADnAAEAAAADAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22aec8956637a99787bd197eacd77acce%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%223.5%22%20y%3D%2216%22%3Ef%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2212.5%22%20y%3D%2221%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2223.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22aec8956637a99787bd197eacd77acce%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2216%22%3Ef%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2221%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2264.5%22%20y%3D%2216%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2216%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2216%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math19c64e078412cbccf2619bcc992%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22aec8956637a99787bd197eacd77acce%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%2216%22%3Ef%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3C%2Fsvg%3E) suma de les
freqüències relatives inferiors o iguals a la í-essima suma de les
freqüències relatives inferiors o iguals a la í-essima
|
Com hem dit, aquestes notacions poden variar en funció del llibre, així en alguns llibres la notació és al revés: fi indica la freqüència absoluta i ni indica la freqüència relativa. Independentment de la notació que es faci
servir, fixa't que sempre: les freqüències absolutes prenen valors enters i la seva suma és el nombre total de dades i les freqüències relatives prenen valors decimals ( entre 0 i 1) i la seva suma dóna 1. Si estan donats en percentatge la suma dóna
100.
Les freqüències acumulades només tenen sentit per variables quantitatives, perquè el que ens indiquen és quantes dades hi ha inferiors o iguals a una donada.
Convé, si no coneixes massa aquests conceptes, que llegeixis amb atenció les pàgines 3-6 del document Conceptes bàsics d'estadística unidimensional que ja t'hem enllaçat abans. Hi trobaràs explicacions detallades i exemples senzills explicats.
Dades agrupades en intervals
En el cas de dades quantitatives continues o algunes discretes amb molts valors, es solen agrupar en intervals. En aquest cas interessa posar una columna amb l'interval [a,b) i una altra columna amb la marca de classe que notarem xi i que és
el punt mig de l'interval format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1564b4c0e54101ac57a0cb68c16'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAABK2hlYWQQC2qxAAACwAAAADZoaGVhCGsXSAAAAvgAAAAkaG10eE2rRkcAAAMcAAAADGxvY2EAHTwYAAADKAAAABBtYXhwBT0FPgAAAzgAAAAgbmFtZaBxlY4AAANYAAABn3Bvc3QB9wD6AAAE%2BAAAACBwcmVwa1uragAABRgAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACsAPf%2F%2FAAAAKwA9%2F%2F%2F%2F1v%2FFAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAEAgABVAtUCqwALAEkBGLIMAQEUExCxAAP2sQEE9bAKPLEDBfWwCDyxBQT1sAY8sQ0D5gCxAAATELEBBuSxAQETELAFPLEDBOWxCwX1sAc8sQkE5TEwEyERMxEhFSERIxEhgAEAVQEA%2FwBV%2FwABqwEA%2FwBW%2FwABAAACAIAA6wLVAhUAAwAHAGUYAbAIELAG1LAGELAF1LAIELAB1LABELAA1LAGELAHPLAFELAEPLABELACPLAAELADPACwCBCwBtSwBhCwB9SwBxCwAdSwARCwAtSwBhCwBTywBxCwBDywARCwADywAhCwAzwxMBMhNSEdASE1gAJV%2FasCVQHAVdVVVQAAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAAAwNSAFUDVgCAA1YAgAAAAAAAAAAoAAAAoQAAASsAAQAAAAMAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2228%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2233%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1564b4c0e54101ac57a0cb68c16%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2228%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2232.5%22%20x2%3D%2270.5%22%20y1%3D%2222.5%22%20y2%3D%2222.5%22%2F%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1564b4c0e54101ac57a0cb68c16%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%2216%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%2239%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E) . El fet de treballar amb intervals fa perdre precisió, perquè
deixem de saber el valor exacte de cada dada, però fa que els càlculs siguin més ràpids.
. El fet de treballar amb intervals fa perdre precisió, perquè
deixem de saber el valor exacte de cada dada, però fa que els càlculs siguin més ràpids.
Veiem un exemple d'una taula on les dades estan recollides per intervals.

Fixa't que a la primera columna s'han separat 5 intervals. En aquest cas tots d'amplitud (distància entre els extrems de l'interval) 200.
A la segona columna s'han calculat les marques de classe, és a dir els punts mitjos dels intervals: format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%2256.5%22%20y1%3D%2221.5%22%20y2%3D%2221.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%228.5%22%20y%3D%2216%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2220.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2241.5%22%20y%3D%2216%22%3E200%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2229.5%22%20y%3D%2238%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2267.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2289.5%22%20y%3D%2227%22%3E100%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22105.5%22%20y%3D%2227%22%3E%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22114.5%22%20x2%3D%22186.5%22%20y1%3D%2221.5%22%20y2%3D%2221.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22129.5%22%20y%3D%2216%22%3E200%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22171.5%22%20y%3D%2216%22%3E400%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%2238%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22197.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22219.5%22%20y%3D%2227%22%3E300%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22235.5%22%20y%3D%2227%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22244.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22249.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22254.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22259.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22264.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e7f1d1b96eeaf004973dfde27e%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22269.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3C%2Fsvg%3E)
I a la darrera columna hi tenim les freqüències absolutes. Per exemple el primer 5 ens indica que de les dades estudiades n'hi ha 5 que estan entre 0 i 200, però no sabem quin valor exacte prenen: (podrien estar molt properes a 0, properes a 200, disperses
dins l'interval, centrades a prop de la marca de classe,...). Ara bé, quan passem a fer càlculs es treballarà com si les 5 dades fossin la marca de classe 100 i això naturalment fa perdre precisió, però aquesta pèrdua de precisió es compensa en la rapidesa
en què es podran fer els càlculs posteriors.
Els gràfics estadístics
Els gràfics estadístics ens permeten fer-nos una idea ràpida i visual sobre el comportament de la variable estudiada a partir d'un dibuix. N'hi ha de molts tipus. Els més importants són:
Diagrama de barres i polígon de freqüències
Aquests diagrames es fan amb variables qualitatives, o quantitatives discretes. Per fer-los cal:
- Dibuixar els eixos de coordenades.
- A l'eix d'abscisses es representa el valor de la variable i a l'eix d'ordenades la freqüència absoluta (o relativa).
- Per cada valor es dibuixa una barra que tingui com alçada la freqüència absoluta (o relativa)
- El polígon de freqüències es pot fer unint els punts mitjos dels extrems d'aquestes barres.
 |
 |
|---|
Histograma
És com el diagrama de barres però per variables agrupades en intervals.
- Cal dibuixar els eixos
- A l'eix d'abscisses es dibuixen els intervals i a l'eix d'ordenades les freqüències
- Per cada interval dibuixem un rectangle amb àrea proporcional a la freqüència. Si tots els intervals tenen la mateixa amplitud , tots els rectangles tenen la mateixa amplada i l'altura correspon a la freqüència

Diagrama de sectors
El podem fer per qualsevol tipus de variable
- Es dibuixa un cercle o semicercle i es divideix en tants sectors com valors pren la variable. L'amplitud de cada sector ha de ser proporcional a la freqüència absoluta o relativa.
- Per calcular l'amplitud de cada sector utilitzarem la següent fórmula.
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1b8792391127a04fc1824856849'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAERjdnQgDVUNBwAAAWAAAAA6Z2x5ZoPi2VsAAAGcAAABf2hlYWQQC2qxAAADHAAAADZoaGVhCGsXSAAAA1QAAAAkaG10eE2rRkcAAAN4AAAAEGxvY2EAHTwYAAADiAAAABRtYXhwBT0FPgAAA5wAAAAgbmFtZaBxlY4AAAO8AAABn3Bvc3QB9wD6AAAFXAAAACBwcmVwa1uragAABXwAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADAAAAAIAAgAAgAAAD0AsAC3%2F%2F8AAAA9ALAAt%2F%2F%2F%2F8T%2FUv9MAAEAAAAAAAAAAAAAAVQDLACAAQAAVgAqAlgCHgEOASwCLABaAYACgACgANQAgAAAAAAAAAArAFUAgACrANUBAAErAAcAAAACAFUAAAMAA6sAAwAHAAAzESERJSERIVUCq%2F2rAgD%2BAAOr%2FFVVAwAAAgCAAOsC1QIVAAMABwBlGAGwCBCwBtSwBhCwBdSwCBCwAdSwARCwANSwBhCwBzywBRCwBDywARCwAjywABCwAzwAsAgQsAbUsAYQsAfUsAcQsAHUsAEQsALUsAYQsAU8sAcQsAQ8sAEQsAA8sAIQsAM8MTATITUhHQEhNYACVf2rAlUBwFXVVVUAAgBVAdYBqwMrAAsAFwBJGAGwGBCxCAX0sRIF9LEPBfSxDAX0sQIF9LEZBfSzCxUFDxA8PDwAsBgQsQsC9LEPBfSxEgX0sRUF9LEFBfSzCAwCEhA8PDwwMQAWFRQGIy4BNzQ2HwE0JiMmBhUUFhcyNgFWVVVWVVYBVVVVKisqKysqKyoDKlVVVVUBVFZVVQGqKyoBKisrKgEqAAEAgAFVAOsBwAADABsYAbAEELEAA%2FSxAgP0sQUD9ACwBBCxAwb0MDETMxUjgGtrAcBrAAABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAEA1IAVQNWAIACAABVAWsAgAAAAAAAAAAoAAAAsgAAAUwAAAF%2FAAEAAAAEAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2232%22%3E%26%23x3B1%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2237%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2222.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2244.5%22%20y%3D%2232%22%3E360%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%2232%22%3E%26%23xB0%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2270.5%22%20y%3D%2232%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22aec8956637a99787bd197eacd77acce%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2232%22%3Ef%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2237%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22106.5%22%20x2%3D%22166.5%22%20y1%3D%2226.5%22%20y2%3D%2226.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2216%22%3E360%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%2216%22%3E%26%23xB0%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b8792391127a04fc1824856849%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2216%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22136.5%22%20y%3D%2243%22%3EN%3C%2Ftext%3E%3C%2Fsvg%3E) (fixeu-vos que podeu fer-ho aplicant la regla de tres)
(fixeu-vos que podeu fer-ho aplicant la regla de tres)
Paràmetres estadístics
Un cop tenim les dades endreçades en una taula, en el cas de les variables quantitatives interessa buscar-ne alguns paràmetres que ens aportin informació a partir d'un sol nombre.Hi ha paràmetres de molts tipus: de centralització, de dispersió, de simetria, de curtosis, etc, però ens centrarem bàsicament en els dos primers tipus.
Mesures de centralització
Ens indiquen on es situen els valors centrals de la distribució. Les principals són:
| NOM | COM ES CALCULA |
Mitjana aritmètica  |
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%2211.5%22%20y1%3D%2245.5%22%20y2%3D%2245.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2261%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2261%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2232.5%22%20x2%3D%2272.5%22%20y1%3D%2255.5%22%20y2%3D%2255.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2246.5%22%20y%3D%2213%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2246.5%22%20y%3D%2237%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2235.5%22%20y%3D%2250%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2244.5%22%20y%3D%2250%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2255.5%22%20y%3D%2250%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2239%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2253.5%22%20y%3D%2272%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2261%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2295.5%22%20x2%3D%22180.5%22%20y1%3D%2255.5%22%20y2%3D%2255.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2231%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22108.5%22%20y%3D%2245%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%2250%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22128.5%22%20y%3D%2250%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%2250%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2242%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22153.5%22%20y%3D%2247%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1777071113da211ffee1cac1b5f%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22160.5%22%20y%3D%2242%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22171.5%22%20y%3D%2242%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22177.5%22%20y%3D%2247%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22138.5%22%20y%3D%2272%22%3EN%3C%2Ftext%3E%3C%2Fsvg%3E)
És el valor que tindrien les dades si totes fossin iguals i sumessin el mateix. |
| Mediana Me |
Si la N és senar Me = dada que ocupa el lloc Si la N és parell Me = mitjana de les dades que ocupen el lloc És el valor que està just al mig de la distribució. La meitat de dades són iguals o superiors a la mediana i la meitat menors o iguals.
|
| Moda Mo | És la dada que té més freqüència, és a dir la que més és repeteix |
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%2242.5%22%20y1%3D%2221.5%22%20y2%3D%2221.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2216%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math117e62166fc8586dfa4d1bc0e17%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2224.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2216%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2222.5%22%20y%3D%2238%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E)
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%2218.5%22%20y1%3D%2220.5%22%20y2%3D%2220.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2215%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2237%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2227.5%22%20y%3D%2226%22%3Ei%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2236.5%22%20x2%3D%2252.5%22%20y1%3D%2220.5%22%20y2%3D%2220.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2244.5%22%20y%3D%2215%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2244.5%22%20y%3D%2237%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math117e62166fc8586dfa4d1bc0e17%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%2226%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2226%22%3E1%3C%2Ftext%3E%3C%2Fsvg%3E)
Convé molt que llegeixis amb deteniment els detalls i exemples que trobaràs en aquest document, sobretot fixa't molt bé en la interpretació de cada paràmetre: Mesures de centralització.
Mesures de dispersió
Fixa't en aquestes dues distribucions de dades:
A:1, 4, 4, 9.
B: 4, 4, 4, 4, 4, 5, 5, 6
En el cas A: la Mo=4, la Me=4 i la = 4,5.
En el cas B: la Mo=4, la Me=4 i la = 4,5.
Observa que coincideixen els tres paràmetres de centralització, en canvi a cop d'ull es veu que es tracta de dues distribucions prou diferents. Això ens fa pensar que ens calen altres paràmetres per fer un bon estudi.
Les mesures de dispersió ens donen una idea del grau de separació de les dades de la distribució.
Aquí tenim les fórmules principals. És especialment important que recordeu i sapigueu aplicar la fórmula de la variància i de la desviació típica. Observeu que es donen dues fórmules alternatives pel càlcul de la variància. Convé saber les dues i utilitzar
la que més convingui segons quines dades coneguem. A ser possible farem servir la segona opció, ja que això ens evitarà haver d'anar introduint parèntesis a la calculadora.
| NOM | COM ES CALCULA |
| Rang o recorregut R | format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2216%22%3ER%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2222.5%22%20y%3D%2216%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2235.5%22%20y%3D%2216%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2246.5%22%20y%3D%2221%22%3Em%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2255.5%22%20y%3D%2221%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%2221%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2216%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2299.5%22%20y%3D%2221%22%3Em%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22111.5%22%20y%3D%2221%22%3En%3C%2Ftext%3E%3C%2Fsvg%3E) |
Desviació mitjana  |
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'brack_sm47dfc8ff4929ef7202a7f1c'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7PH4UAAADMAAAATmNtYXA3kjw6AAABHAAAADRjdnQgAQYDiAAAAVAAAAASZ2x5ZkyYQ7YAAAFkAAAAWWhlYWQLyR8fAAABwAAAADZoaGVhAq0XCAAAAfgAAAAkaG10eDEjA%2FUAAAIcAAAACGxvY2EAAEKZAAACJAAAAAxtYXhwBJsEcQAAAjAAAAAgbmFtZW7QvZAAAAJQAAAB5XBvc3QArQBVAAAEOAAAACBwcmVwu5WEAAAABFgAAAAHAAACDAGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg9AMD%2FP%2F8AAABVAABAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAA9AL%2F%2FwAA9AL%2F%2Fwv%2FAAEAAAAAAAABVABUAQAAKwCMAIAAqAAHAAAAAgAAAAAA1QEBAAMABwAAMTMRIxcjNTPV1auAgAEB1qsAAQBQAAAAoAFUAAMAHxgBsAMvsAA8sQIC9bABPACxAwA%2FsAI8fLEABvWwATwTMxEjUFBQAVT%2BrAAAAAABAAAAAQAAix6x7F8PPPUAAwQA%2F%2F%2F%2F%2F9Wt7mT%2F%2F%2F%2F%2F1a3uZP%2BA%2F%2F8B1gFYAAAACgACAAEAAAAAAAEAAAFU%2F%2F8AABdw%2F4D%2FgAHWAAEAAAAAAAAAAAAAAAAAAAACANUAAADwAFAAAAAAAAAAIQAAAFkAAQAAAAIACgACAAAAAAACAIAEAAAAAAAEAABlAAAAAAAAABUBAgAAAAAAAAABACYAAAAAAAAAAAACAA4AJgAAAAAAAAADAEQANAAAAAAAAAAEACYAeAAAAAAAAAAFABYAngAAAAAAAAAGABMAtAAAAAAAAAAIABwAxwABAAAAAAABACYAAAABAAAAAAACAA4AJgABAAAAAAADAEQANAABAAAAAAAEACYAeAABAAAAAAAFABYAngABAAAAAAAGABMAtAABAAAAAAAIABwAxwADAAEECQABACYAAAADAAEECQACAA4AJgADAAEECQADAEQANAADAAEECQAEACYAeAADAAEECQAFABYAngADAAEECQAGABMAtAADAAEECQAIABwAxwBCAHIAYQBjAGsAZQB0AHMAIABzAG0AYQBsAGwAIABzAGkAegBlAFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAQgByAGEAYwBrAGUAdABzACAAcwBtAGEAbABsACAAcwBpAHoAZQBCAHIAYQBjAGsAZQB0AHMAIABzAG0AYQBsAGwAIABzAGkAegBlAFYAZQByAHMAaQBvAG4AIAAyAC4AMEJyYWNrZXRzX3NtYWxsX3NpemUATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAAAqgBVAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAo2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2261%22%3ED%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2219.5%22%20y%3D%2261%22%3EM%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2261%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2247.5%22%20x2%3D%22155.5%22%20y1%3D%2255.5%22%20y2%3D%2255.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%2213%22%3Ek%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%2237%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2250%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2250%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2270.5%22%20y%3D%2250%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%2275.5%22%20y%3D%2226%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%2275.5%22%20y%3D%2231%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%2275.5%22%20y%3D%2236%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%2275.5%22%20y%3D%2241%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%22124.5%22%20y%3D%2226%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%22124.5%22%20y%3D%2231%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%22124.5%22%20y%3D%2236%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22brack_sm47dfc8ff4929ef7202a7f1c%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22start%22%20x%3D%22124.5%22%20y%3D%2241%22%3E%26%23xF402%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2239%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%2234%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22111.5%22%20x2%3D%22122.5%22%20y1%3D%2218.5%22%20y2%3D%2218.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22117.5%22%20y%3D%2234%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22135.5%22%20y%3D%2234%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22146.5%22%20y%3D%2234%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22152.5%22%20y%3D%2239%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%2272%22%3EN%3C%2Ftext%3E%3C%2Fsvg%3E) |
Variància  |
%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xB2%3B%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmrow%3E%3Cmi%20mathvariant%3D%22bold%22%3Ei%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%3D%3C%2Fmo%3E%3Cmn%20mathvariant%3D%22bold%22%3E1%3C%2Fmn%3E%3C%2Fmrow%3E%3Cmi%20mathvariant%3D%22bold%22%3Ek%3C%2Fmi%3E%3C%2Fmunderover%3E%3C%2Fmstyle%3E%3Cmi%20mathvariant%3D%22bold%22%3EN%3C%2Fmi%3E%3C%2Fmfrac%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eo%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmsup%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23x3C3%3B%3C%2Fmi%3E%3Cmn%20mathvariant%3D%22bold%22%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3Cmo%20mathvariant%3D%22bold%22%3E%3D%3C%2Fmo%3E%3Cmfrac%3E%3Cmrow%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunderover%3E%3Cmrow%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmsup%3E%3Cmi%20mathvariant%3D%22bold%22%3Ex%3C%2Fmi%3E%3Cmn%20mathvariant%3D%22bold%22%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3Cmi%20mathvariant%3D%22bold%22%3E%26%23xEE%3B%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmrow%3E%3Cmi%20mathvariant%3D%22bold%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold%22%3Ek%3C%2Fmi%3E%3C%2Fmunderover%3E%3C%2Fmstyle%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%20mathvariant%3D%22bold%22%3En%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold%22%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmrow%3E%3Cmi%20mathvariant%3D%22bold%22%3EN%3C%2Fmi%3E%3C%2Fmfrac%3E%3Cmo%20mathvariant%3D%22bold%22%3E-%3C%2Fmo%3E%3Cmsup%3E%3Cmenclose%20notation%3D%22top%22%3E%3Cmi%20mathvariant%3D%22bold%22%3EX%3C%2Fmi%3E%3C%2Fmenclose%3E%3Cmn%20mathvariant%3D%22bold%22%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math165f1a8153dd73e7dd544abd465'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAExjdnQgDVUNBwAAAWgAAAA6Z2x5ZoPi2VsAAAGkAAABuGhlYWQQC2qxAAADXAAAADZoaGVhCGsXSAAAA5QAAAAkaG10eE2rRkcAAAO4AAAAFGxvY2EAHTwYAAADzAAAABhtYXhwBT0FPgAAA%2BQAAAAgbmFtZaBxlY4AAAQEAAABn3Bvc3QB9wD6AAAFpAAAACBwcmVwa1uragAABcQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADgAAAAKAAgAAgACAD0AtyIRIhL%2F%2FwAAAD0AtyIRIhL%2F%2F%2F%2FE%2F0vd8t3yAAEAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAACAIAA6wLVAhUAAwAHAGUYAbAIELAG1LAGELAF1LAIELAB1LABELAA1LAGELAHPLAFELAEPLABELACPLAAELADPACwCBCwBtSwBhCwB9SwBxCwAdSwARCwAtSwBhCwBTywBxCwBDywARCwADywAhCwAzwxMBMhNSEdASE1gAJV%2FasCVQHAVdVVVQABAIABVQDrAcAAAwAbGAGwBBCxAAP0sQID9LEFA%2FQAsAQQsQMG9DAxEzMVI4BrawHAawABAIAAAAMrAysADwBKGAGwEBCxBAP2sAA8sQkD9bALPLEGC%2FWwDjyxEQPmsQcG%2FbANPACxBAA%2FsQgF%2FbEDCTw8sQYF7bEAAj%2BxDAX9sQsBPDyxDgX9MTATFQkBFSE1IxUhCQEhFTM1gAEr%2FtUCqyv%2BAAEr%2FtUCACsDK1X%2B%2F%2F6AVatWAYABAVarAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAABQNSAFUDVgCAAWsAgAOsAIADVgCAAAAAAAAAACgAAACyAAAA5QAAAW4AAAG4AAEAAAAFAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2267%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2260%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2228.5%22%20y%3D%2267%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2239.5%22%20x2%3D%22129.5%22%20y1%3D%2261.5%22%20y2%3D%2261.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2213%22%3Ek%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2252.5%22%20y%3D%2239%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2267.5%22%20y%3D%2236%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2236%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2280.5%22%20y%3D%2241%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2236%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22100.5%22%20x2%3D%22111.5%22%20y1%3D%2220.5%22%20y2%3D%2220.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2236%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%2236%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%2236%22%3E%26%23xB2%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%2256%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2282.5%22%20y%3D%2256%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2293.5%22%20y%3D%2256%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%2278%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2267%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22168.5%22%20y%3D%2267%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22178.5%22%20y%3D%2260%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22191.5%22%20y%3D%2267%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22202.5%22%20x2%3D%22272.5%22%20y1%3D%2261.5%22%20y2%3D%2261.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22225.5%22%20y%3D%2214%22%3Ek%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22215.5%22%20y%3D%2240%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22231.5%22%20y%3D%2237%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22239.5%22%20y%3D%2230%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22245.5%22%20y%3D%2242%22%3E%26%23xEE%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22225.5%22%20y%3D%2256%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22252.5%22%20y%3D%2237%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22263.5%22%20y%3D%2237%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22269.5%22%20y%3D%2242%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22238.5%22%20y%3D%2278%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math165f1a8153dd73e7dd544abd465%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22284.5%22%20y%3D%2267%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22293.5%22%20x2%3D%22304.5%22%20y1%3D%2251.5%22%20y2%3D%2251.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22299.5%22%20y%3D%2267%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22308.5%22%20y%3D%2260%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E) |
Desviació típica 
|
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2222%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f39f8317fbdb1988ef4c628eb%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2222%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2212%2C-20%2011%2C-20%205%2C0%202%2C-8%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(30.5%2C23.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%225%2C0%202%2C-8%200%2C-7%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(30.5%2C23.5)%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2242.5%22%20x2%3D%2263.5%22%20y1%3D%223.5%22%20y2%3D%223.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2249.5%22%20y%3D%2222%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2215%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E) |
El coeficient de variació
El coeficient de variació serveix per comparar dues distribucions diferents. Ens indica quina de les distribucions té menys dispersió i per tant una mitjana més representativa.
Quan més petit és el CV menys dispersió i més representativitat té la mitjana aritmètica de la distribució.
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2226%22%3EC%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2218.5%22%20y%3D%2226%22%3EV%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f39f8317fbdb1988ef4c628eb%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2226%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2245.5%22%20x2%3D%2260.5%22%20y1%3D%2220.5%22%20y2%3D%2220.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2253.5%22%20y%3D%2215%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2247.5%22%20x2%3D%2258.5%22%20y1%3D%2222.5%22%20y2%3D%2222.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2253.5%22%20y%3D%2238%22%3EX%3C%2Ftext%3E%3C%2Fsvg%3E) es calcula dividint la desviació típica entre la mitjana aritmètica.
es calcula dividint la desviació típica entre la mitjana aritmètica.
Exercici resolt: estadística unidimensional
Les dades (en blau) de la taula inferior mostren els resultats d'uns esportistes en una prova de salt de perxa.
a) Completa la taula de freqüències omplint les caselles que falten.
|
mesura salt (metres) |
marca de classe |
Nombre d'esportistes (Freqüència absoluta) |
Freqüència absoluta acumulada |
Freqüència relativa arrodonir a dos decimals |
Freqüència relativa acumulada arrodonir a dos decimals |
xi*ni |
ni·xi 2
|
| [2, 2.5) | 6 | ||||||
| [2.5, 3) | 12 | ||||||
| [3, 3.5) | 15 | ||||||
| [3.5, 4) | 4 | ||||||
| TOTALS |
b) Calcula el rang.
c) Calcula la mitjana aritmètica.
d) Calcula quin % d'esportistes va saltar més 3.5 m.
e) Calcula la variància i la desviació típica.
a) Resposta
|
mesura salt (metres) |
marca de classe |
Nombre d'esportistes (Freqüència absoluta) |
Freqüència absoluta acumulada |
Freqüència relativa arrodonir a dos decimals |
Freqüència relativa acumulada arrodonir a dos decimals |
xi*ni |
ni·xi 2
|
| [2, 2.5) | 2.25 | 6 | 6 | 6/37=0.16 | 0.16 | 13.5 | 30,375
|
| [2.5, 3) | 2.75 | 12 | 18 | 12/37=0.32 | 0.48 | 33 | 90,75
|
| [3, 3.5) | 3.25 | 15 | 33 | 15/37=0.41 | 0.89 | 48.75 | 158,4375 |
| [3.5, 4) | 3.75 | 4 | 37 | 4/37=0.11 | 1 | 15 | 56,25 |
| TOTAL | 37 | 1 | 110.25 | 335,8125 |
b) El rang d'una variable estadística és la diferència entre el valor més gran i el valor més petit. Rang (X) =4-2=2
c) La mitjana aritmètica es calcula amb la fórmula:

format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%228.5%22%20y1%3D%2211.5%22%20y2%3D%2211.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2227%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11824c643d1feb4da18b28ed527%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2217.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2228.5%22%20x2%3D%2281.5%22%20y1%3D%2221.5%22%20y2%3D%2221.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2216%22%3E110%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11824c643d1feb4da18b28ed527%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2216%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%2216%22%3E25%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2255.5%22%20y%3D%2238%22%3E37%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11824c643d1feb4da18b28ed527%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22105.5%22%20y%3D%2227%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11824c643d1feb4da18b28ed527%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22112.5%22%20y%3D%2227%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22124.5%22%20y%3D%2227%22%3E98%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22143.5%22%20y%3D%2227%22%3Em%3C%2Ftext%3E%3C%2Fsvg%3E)
d) Cal mirar la freqüència relativa de l'interval [3.5 , 4) i veiem que és 4/37=0,11→11%
És a dir , hi ha 4 esportistes dels 37 que hi ha en total que han saltat més de 3.5 m. O sigui l'11%
e) Disposem de dues fórmules pel càlcul de la variància, però a partir de la taula (darrera columna) ens convé fer servir
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2266%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%2259%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%2266%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2237.5%22%20x2%3D%22100.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2213%22%3Ek%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2239%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2236%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2272.5%22%20y%3D%2229%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2241%22%3E%26%23xEE%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2255%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%2236%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2236%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2297.5%22%20y%3D%2241%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2277%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%2266%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22118.5%22%20x2%3D%22128.5%22%20y1%3D%2250.5%22%20y2%3D%2250.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%2266%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22132.5%22%20y%3D%2259%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E)
Substituïm els valors de la taula i els ja obtinguts a la fórmula:
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2266%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%2259%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%2266%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2237.5%22%20x2%3D%22100.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2213%22%3Ek%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2239%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2236%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2272.5%22%20y%3D%2229%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2241%22%3E%26%23xEE%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2255%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%2236%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2236%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2297.5%22%20y%3D%2241%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2277%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%2266%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22118.5%22%20x2%3D%22128.5%22%20y1%3D%2250.5%22%20y2%3D%2250.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%2266%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22132.5%22%20y%3D%2259%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22144.5%22%20y%3D%2266%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22155.5%22%20x2%3D%22226.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22170.5%22%20y%3D%2255%22%3E335%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22186.5%22%20y%3D%2255%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22207.5%22%20y%3D%2255%22%3E8125%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22191.5%22%20y%3D%2277%22%3E37%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22236.5%22%20y%3D%2266%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22248.5%22%20y%3D%2266%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22255.5%22%20y%3D%2266%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22267.5%22%20y%3D%2266%22%3E98%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22279.5%22%20y%3D%2259%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22291.5%22%20y%3D%2266%22%3E%26%23x2248%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22304.5%22%20y%3D%2266%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e89352fa595bc56a68d6ef2afa%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22311.5%22%20y%3D%2266%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22332.5%22%20y%3D%2266%22%3E1956%3C%2Ftext%3E%3C%2Fsvg%3E) m
m
Estadística bidimensional
Una variable estadística bidimensional
és la que resulta d'observar conjuntament dues característiques X i Y relatives a una mateixa població o mostra.
Cada observació d’un element de la mostra està representada per un parell de valors (x,y).
No
es tracta de fer un estudi aïllat de cadascuna de les variables, sinó
d’estudiar la relació o dependència que pugui existir entre elles, en el
cas que aquesta relació existeixi.
Exemple: La variable (X,Y) que recull les notes finals de matemàtiques i física respectivament dels alumnes d'una classe. Aquesta variable pot prendre els valors:
(X,Y)={(0,0),(0,1),(0,2),...(0,10),(1,0),(1,1),(1,2)....(1,10),(2,0),(2,1)...(2,10),........(10,0),(10,1),...(10,10)}
El conjunt de totes les dades procedents de l'observació d'una variable estadística bidimensional s'anomena distribució bidimensional.
Taules bidimensionals
La manera més habitual d’expressar els valors obtinguts en una distribució estadística bidimensional és mitjançant una taula de contingència o taula de doble entrada.
Al marge superior de la taula s’escriuen els resultats d’una de les variables i al marge esquerre, els valors de l’altra variable.
En les caselles de la taula s’indiquen simultàniament les freqüències absolutes, les freqüències relatives o els percentatges corresponents a les dues variables.
També s’acostuma a afegir al final de cada fila i de cada columna les anomenades distribucions marginals, que donen les distribucions unidimensionals de cadascuna de les variables per separat.
Les distribucions marginals de les variables X i Y s’obtenen a partir de la taula de contingència, considerant cada variable per separat. Representen les freqüències dels valors d’una variable, independentment dels valors de l’altra.
A partir de les distribucions marginals podem calcular la mitjana i la desviació típica de cadascuna de les variables, estudiant-les com una variable unidimensional.
Exemple
S'ha realitzat una enquesta a 50 persones preguntant pel nombre de persones (X) que habiten la llar familiar i el nombre d'habitacions (Y) que té la casa. Els resultats obtinguts (xi ,yj) són els següents:
(3,4),(2,1),(2,4),(3,2),(3,2),(3,3),(2,1),(2,2),(2,2),(4,5),
(4,3),(2,2),(5,4),(4,3),(4,2),(4,3),(4,3),(3,2),(3,4),(4,4),
(5,4),(6,4),(3,2),(2,2),(2,2),(4,5),(4,3),(2,3),(3,3),(3,4),
(3,2),(5,3),(6,5),(6,4),(2,2),(5,4),(4,3),(4,2),(4,3),(4,3),
(1,1),(2,4),(3,2),(3,2),(1,2),(4,3),(4,4),(1,2),(4,5),(3,3)
La taula de doble entrada següent mostra la distribució de dades obtingudes

La fila final en color blau correspon a la variable marginal de la X, observa que senzillament cal sumar totes les freqüències per columnes.
La columna final en color blau correspon a la variable marginal de la Y, observa que senzillament cal sumar totes les freqüències per files.
També podem considerar les variables X i Y com a variables unidimensionals si volem trobar els seus paràmetres estadístics com ara la mitjana i la desviació tipus

Exemple 2
En casos de poques dades o dades no repetides, és habitual que les taules es donin només en dues files (o dues columnes)
Per exemple una taula com aquesta
![]()
ens indica en cada columna l'observació d'un individu respecte a les dues variables observades.
Suposem que en aquest cas
X=nombre de vegades que va necessitar un individu per aprovar la teòrica del carnet de conduir.
i Y=nombre de vegades que va necessitar un individu per aprovar les pràctiques del carnet de conduir.
Doncs bé, aquesta taula treballa amb una mostra de 10 individus (les 10 columnes).
El primer individu va aprovar a la primera la teòrica i a la tercera les pràctiques, el segon va aprovar a la segona la teòrica i a la cinquena les pràctiques,....
En aquests casos de poques dades no és necessari fer la taula de contingència.
Què vol dir dependència estadística?
Entre dues variables diem que hi ha dependència estadística quan els valors que pren una variable estan relacionats d'alguna manera amb els valors que pren l'altra, possiblement no d'una manera exacte.
Aquesta dependència pot ser de molts tipus: quadràtica, exponencial, lineal, funcional, .... En general l'estudi del curs es basarà en la dependència lineal (és a dir, estudiar si el comportament d'una variable respecte a l'altra s'aproxima a una recta).
Quan les variables són de tipus quantitatiu, l'estudi de la dependència estadística es coneix com el problema de "regressió", i l'anàlisi del grau de dependència que hi ha entre les variables es coneix com el problema de correlació. L'objectiu principal de la regressió és descobrir la manera en què es relacionen.
Exemple
En una taula de pesos i altures de 10 persones es pot suposar que la variable "Alçada" influeix sobre la variable "Pes" en el sentit que pesos grans vénen explicats per valors grans d'altura (en general). De les dues variables a estudiar, que anomenarem amb X i Y, anomenarem a la X VARIABLE INDEPENDENT , i a l'altra (la Y) l'anomenarem VARIABLE DEPENDENT.
En la majoria dels casos la relació entre les variables és mútua, i és difícil saber quina variable influeix sobre l'altra. En l'exemple anterior, a una persona que pesa poc li suposarem menor altura i a una persona de poca altura li suposarem un pes més baix. És a dir, es pot admetre que cada variable influeix sobre l'altra de forma natural i per igual. Un exemple més clar on distingir entre variable independent i dependent és aquell on s'anota, de cada alumne d'una classe, el seu temps d'estudi (en hores) i la seva nota d'examen.
En aquest cas un petit temps d'estudi tendirà a obtenir una nota més baixa, i una nota bona ens indicarà que potser l'alumne ha estudiat molt. No obstant això, a l'hora de determinar quina variable depèn de l'altra, és clar que el "temps d'estudi" influeix sobre la "nota d'examen" i no al contrari, ja que l'alumne primer estudia un temps que pot decidir lliurement, i després obté una nota que ja no decideix arbitràriament. Per tant,
X = Temps d'estudi (variable independent)
Y = Nota d'examen (variable dependent)
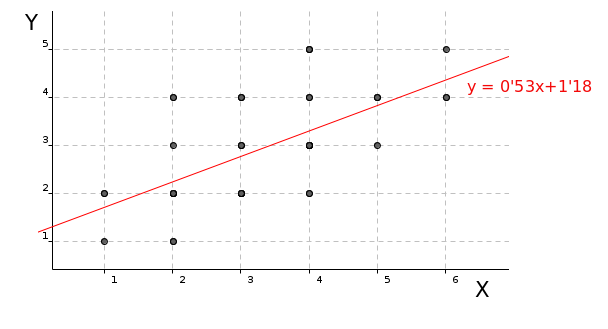
Per detectar si hi ha algun tipus de relació de dependència entre dues variables és molt útil dibuixar-les per a visualitzar com és aquesta relació. Per això se sol utilitzar un gràfic anomenat núvol de punts o diagrama de dispersió consistent en representar sobre uns eixos de coordenades tots els parells de valors que apareguin en la mostra.
Habitualment es representa en l'eix d'abscises (X) la variable independent, i en l'eix de les ordenades (Y) la variable dependent.
En realitzar un diagrama de dispersió entre dues variables X i Y poden sorgir algunes de les següents situacions:
- Una relació matemàtica exacta entre X i Y, és a dir, donat un valor de X podem calcular el valor de la variable Y corresponent mitjançant una fórmula (dependència matemàtica).
- No s'observa cap relació entre les variables, és a dir, conèixer X no serveix en absolut per calcular Y (independència estadística).
- Tot i que no hi hagi una dependència matemàtica exacta, si que s'observa una relació aproximada (dependència estadística). Els punts s'acosten a la gràfica d'una funció
Exemples :

|

|
Hi ha una relació matemàtica exacte entre X i Y ja que |
|
|

|
No hi ha cap relació entre X i Y |
|
|
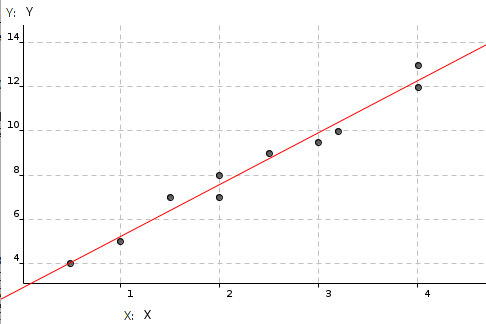
|
S'observa una relació aproximada o dependència estadística (i és lineal) |
|
|

|
S'observa una relació aproximada o dependència estadística (i no és lineal) |
%3C%2Fmo%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math143f4d31b04031e49f5eb18baba'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAAA%2FGhlYWQQC2qxAAACkAAAADZoaGVhCGsXSAAAAsgAAAAkaG10eE2rRkcAAALsAAAADGxvY2EAHTwYAAAC%2BAAAABBtYXhwBT0FPgAAAwgAAAAgbmFtZaBxlY4AAAMoAAABn3Bvc3QB9wD6AAAEyAAAACBwcmVwa1uragAABOgAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACAD0iEv%2F%2FAAAAPSIS%2F%2F%2F%2FxN3wAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAIAgADrAtUCFQADAAcAZRgBsAgQsAbUsAYQsAXUsAgQsAHUsAEQsADUsAYQsAc8sAUQsAQ8sAEQsAI8sAAQsAM8ALAIELAG1LAGELAH1LAHELAB1LABELAC1LAGELAFPLAHELAEPLABELAAPLACELADPDEwEyE1IR0BITWAAlX9qwJVAcBV1VVVAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAAAwNSAFUDVgCAA1YAgAAAAAAAAAAoAAAAsgAAAPwAAQAAAAMAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2218%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2217.5%22%20y%3D%2218%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2229.5%22%20y%3D%2218%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2235.5%22%20y%3D%2218%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2247.5%22%20y%3D%2218%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2218%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2266.5%22%20y%3D%2218%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2272.5%22%20y%3D%2211%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E)



El problema de trobar una relació funcional entre dues variables és molt complex, ja que hi ha infinitat de funcions de formes diferents. El cas més senzill de relació entre dues variables és la relació LINEAL, és a dir que Y = a + b X . És l'equació d'una recta on a i b són nombres, que és el cas en què ens centrarem en aquest curs
En concret el tercer núvol de punts es "semblant " a una recta. Si sabéssim calcular l'equació d'aquesta recta, es podria "aproximar" el valor de Y un cop conegut el valor de X. El problema de trobar l'equació de la recta que més s'assembli (o que millor s'ajusti) al núvol de punts es coneix com regressió lineal.
El primer núvol de punts és similar a l'últim, encara que en aquests cassos els núvols de punts s'aproximen a una corba i no a una recta. Trobar l'equació d'aquesta corba seria un problema de regressió no lineal.
Fórmules per variables bidimensioanals
Amb les variables bidimensionals, un cop s'han recollit les dades en taules interessa fer càlculs que ens ajudin a determinar el grau de dependència entre les dues variables.
La dependència entre dues variables pot ser lineal (recta) o funcional (altre tipus de funció). Per estudiar si dues variables tenen dependència lineal tenim diversos paràmetres.
Covariància
Tenim dues possibles fórmules per calcular la covariància entre dues variables X i Y. Triarem una o altra depenent del tipus de dades que disposem, tot i que en general és més ràpida la primera doncs no s'han d'introduir parèntesis a la calculadora.%3C%2Fmo%3E%3Cmo%3E(%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%3E-%3C%2Fmo%3E%3Cmover%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmo%3E%26%23xAF%3B%3C%2Fmo%3E%3C%2Fmover%3E%3Cmo%3E)%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmi%3EN%3C%2Fmi%3E%3C%2Fmfrac%3E%3C%2Fmenclose%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'horizontalbf65417dcecc7f2b0006e'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMlJxIOAAAADMAAAATmNtYXCwg0j%2FAAABHAAAADRjdnQgAAcAAAAAAVAAAAACZ2x5ZuwE1kUAAAFUAAAAO2hlYWQNciGiAAABkAAAADZoaGVhBusXCAAAAcgAAAAkaG10eGjtB6sAAAHsAAAACGxvY2EAAYSYAAAB9AAAAAxtYXhwBLEEbgAAAgAAAAAgbmFtZReja%2F8AAAIgAAAByXBvc3QB9wD6AAAD7AAAACBwcmVwu5WEAAAABAwAAAAHAAACRwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAACOv8xEDev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAI6%2F%2F%2FwAAI6%2F%2F%2F9xSAAEAAAAAAAcAAAABAAABVQGrAasAAwAjGAGwBBCwATywARCwAtSwAhCwBTwAsAQQsAHUsAEQsADUMDERFSE1AasBq1ZWAAABAAAAAQAARVMXc18PPPUAAwQA%2F%2F%2F%2F%2F9Wt7tH%2F%2F%2F%2F%2F1a3u0QAAAAADAAMAAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2F%2FwMAAAEAAAAAAAAAAAAAAAAAAAACAyAAAAGrAAAAAAAAAAAAAAAAADsAAQAAAAIADQACAAAAAAACAIAEAAAAAAAEAABfAAAAAAAAABUBAgAAAAAAAAABAB4AAAAAAAAAAAACAA4AHgAAAAAAAAADADwALAAAAAAAAAAEAB4AaAAAAAAAAAAFABYAhgAAAAAAAAAGAA8AnAAAAAAAAAAIABwAqwABAAAAAAABAB4AAAABAAAAAAACAA4AHgABAAAAAAADADwALAABAAAAAAAEAB4AaAABAAAAAAAFABYAhgABAAAAAAAGAA8AnAABAAAAAAAIABwAqwADAAEECQABAB4AAAADAAEECQACAA4AHgADAAEECQADADwALAADAAEECQAEAB4AaAADAAEECQAFABYAhgADAAEECQAGAA8AnAADAAEECQAIABwAqwBIAG8AcgBpAHoAbwBuAHQAYQBsACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AMEhvcml6b250YWxfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAAAAwAAAAAAAAH0APoAAAAAAAAAAAAAAAAAAAAAAAAAALkH%2FwACjYUA)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math17c53bbbe5ccdc8df9668d44a51'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAExjdnQgDVUNBwAAAWgAAAA6Z2x5ZoPi2VsAAAGkAAABuGhlYWQQC2qxAAADXAAAADZoaGVhCGsXSAAAA5QAAAAkaG10eE2rRkcAAAO4AAAAFGxvY2EAHTwYAAADzAAAABhtYXhwBT0FPgAAA%2BQAAAAgbmFtZaBxlY4AAAQEAAABn3Bvc3QB9wD6AAAFpAAAACBwcmVwa1uragAABcQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADgAAAAKAAgAAgACAD0AtyIRIhL%2F%2FwAAAD0AtyIRIhL%2F%2F%2F%2FE%2F0vd8t3yAAEAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAACAIAA6wLVAhUAAwAHAGUYAbAIELAG1LAGELAF1LAIELAB1LABELAA1LAGELAHPLAFELAEPLABELACPLAAELADPACwCBCwBtSwBhCwB9SwBxCwAdSwARCwAtSwBhCwBTywBxCwBDywARCwADywAhCwAzwxMBMhNSEdASE1gAJV%2FasCVQHAVdVVVQABAIABVQDrAcAAAwAbGAGwBBCxAAP0sQID9LEFA%2FQAsAQQsQMG9DAxEzMVI4BrawHAawABAIAAAAMrAysADwBKGAGwEBCxBAP2sAA8sQkD9bALPLEGC%2FWwDjyxEQPmsQcG%2FbANPACxBAA%2FsQgF%2FbEDCTw8sQYF7bEAAj%2BxDAX9sQsBPDyxDgX9MTATFQkBFSE1IxUhCQEhFTM1gAEr%2FtUCqyv%2BAAEr%2FtUCACsDK1X%2B%2F%2F6AVatWAYABAVarAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAABQNSAFUDVgCAAWsAgAOsAIADVgCAAAAAAAAAACgAAACyAAAA5QAAAW4AAAG4AAEAAAAFAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%220.5%22%20y1%3D%220.5%22%20y2%3D%2256.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22473.5%22%20x2%3D%22473.5%22%20y1%3D%220.5%22%20y2%3D%2256.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22473.5%22%20y1%3D%220.5%22%20y2%3D%220.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22473.5%22%20y1%3D%2256.5%22%20y2%3D%2256.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%227.5%22%20y%3D%2242%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2216.5%22%20y%3D%2247%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2222.5%22%20y%3D%2247%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2242%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2245.5%22%20x2%3D%22130.5%22%20y1%3D%2236.5%22%20y2%3D%2236.5%22%2F%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2226%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2223%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%2228%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2290.5%22%20y%3D%2223%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2223%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22104.5%22%20y%3D%2228%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22111.5%22%20y%3D%2223%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%2223%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22126.5%22%20y%3D%2228%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2253%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22140.5%22%20y%3D%2242%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%2234%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22154.5%22%20y%3D%2234%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22152.5%22%20y%3D%2242%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22161.5%22%20y%3D%2242%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22167.5%22%20y%3D%2234%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22171.5%22%20y%3D%2234%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22169.5%22%20y%3D%2242%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22226.5%22%20y%3D%2242%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22240.5%22%20y%3D%2242%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22249.5%22%20y%3D%2242%22%3E%26%23xE9%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22257.5%22%20y%3D%2242%22%3E%3A%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22308.5%22%20y%3D%2242%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22317.5%22%20y%3D%2247%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22323.5%22%20y%3D%2247%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22335.5%22%20y%3D%2242%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22346.5%22%20x2%3D%22469.5%22%20y1%3D%2236.5%22%20y2%3D%2236.5%22%2F%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%22359.5%22%20y%3D%2226%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22377.5%22%20y%3D%2223%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22383.5%22%20y%3D%2223%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22389.5%22%20y%3D%2228%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22399.5%22%20y%3D%2223%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22409.5%22%20y%3D%2215%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22413.5%22%20y%3D%2215%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22411.5%22%20y%3D%2223%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22418.5%22%20y%3D%2223%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22424.5%22%20y%3D%2223%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22430.5%22%20y%3D%2223%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22436.5%22%20y%3D%2228%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17c53bbbe5ccdc8df9668d44a51%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22446.5%22%20y%3D%2223%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22456.5%22%20y%3D%2215%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22460.5%22%20y%3D%2215%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22458.5%22%20y%3D%2223%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22465.5%22%20y%3D%2223%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22408.5%22%20y%3D%2253%22%3EN%3C%2Ftext%3E%3C%2Fsvg%3E)
Es pot veure que la variància és com la covariància en cas que les dues variables fossin la mateixa.
Què ens indica el valor de la covariància entre dues variables? L'hem d'interpretar de la següent manera:
Si format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1bf1300290303a745c5f9a70ef1'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAABGGhlYWQQC2qxAAACrAAAADZoaGVhCGsXSAAAAuQAAAAkaG10eE2rRkcAAAMIAAAADGxvY2EAHTwYAAADFAAAABBtYXhwBT0FPgAAAyQAAAAgbmFtZaBxlY4AAANEAAABn3Bvc3QB9wD6AAAE5AAAACBwcmVwa1uragAABQQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACAD4iEv%2F%2FAAAAPiIS%2F%2F%2F%2Fw93wAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAIAgABVAoECqwAFAAsAbBiwQRoAsQAAExCxAAbksQABExCwCTyxAQX1sAo8sAAQsQUD9bECBe2xBAP1sQMF7bAKELELA%2FWxCAXtsQYD9bEHBe0BsAwQsQQD9rIHBgM8PDyxBQT1sgIICzw8PLEABPWyCQoBPDw8sQ0D5gEVDQE1JQE1DQEVJQKA%2FwD%2FAAEA%2FwABAAEB%2Fv8Bq1aAgFaAASpWgIBWgAABAIABVQLVAasAAwAwGAGwBBCxAAP2sAM8sQIH9bABPLEFA%2BYAsQAAExCxAAblsQABExCwATyxAwX1sAI8EyEVIYACVf2rAatWAAEAAAABAADVeM5BXw889QADBAD%2F%2F%2F%2F%2F1joTc%2F%2F%2F%2F%2F%2FWOhNzAAD%2FIASAA6sAAAAKAAIAAQAAAAAAAQAAA%2Bj%2FagAAF3AAAP%2B2BIAAAQAAAAAAAAAAAAAAAAAAAAMDUgBVAwAAgANWAIAAAAAAAAAAKAAAAM4AAAEYAAEAAAADAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2221%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2223.5%22%20y%3D%2221%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1bf1300290303a745c5f9a70ef1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2216%22%3E%26gt%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2248.5%22%20y%3D%2216%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1bf1300290303a745c5f9a70ef1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2260.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1bf1300290303a745c5f9a70ef1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1bf1300290303a745c5f9a70ef1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2216%22%3E%26gt%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22112.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2216%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22157.5%22%20y%3D%2216%22%3E%26%23xE8%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22166.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22175.5%22%20y%3D%2216%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22181.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22187.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22199.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22203.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22209.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22218.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22227.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22234.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22245.5%22%20y%3D%2216%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22254.5%22%20y%3D%2216%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22263.5%22%20y%3D%2216%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22269.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22273.5%22%20y%3D%2216%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22277.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22283.5%22%20y%3D%2216%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22291.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3C%2Fsvg%3E)
Si format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math18ff5aca02e013ba3470d3c3575'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAERjdnQgDVUNBwAAAWAAAAA6Z2x5ZoPi2VsAAAGcAAABvGhlYWQQC2qxAAADWAAAADZoaGVhCGsXSAAAA5AAAAAkaG10eE2rRkcAAAO0AAAAEGxvY2EAHTwYAAADxAAAABRtYXhwBT0FPgAAA9gAAAAgbmFtZaBxlY4AAAP4AAABn3Bvc3QB9wD6AAAFmAAAACBwcmVwa1uragAABbgAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADAAAAAIAAgAAgAAADwAPiIS%2F%2F8AAAA8AD4iEv%2F%2F%2F8X%2FxN3xAAEAAAAAAAAAAAAAAVQDLACAAQAAVgAqAlgCHgEOASwCLABaAYACgACgANQAgAAAAAAAAAArAFUAgACrANUBAAErAAcAAAACAFUAAAMAA6sAAwAHAAAzESERJSERIVUCq%2F2rAgD%2BAAOr%2FFVVAwAAAgCAAFUCgAKrAAUACwBsGLBBGgCxAAATELEABuSxAAETELAJPLEBBfWwCjywABCxBQP1sQIF7bEEA%2FWxAwXtsAoQsQsD9bEIBe2xBgP1sQcF7QGwDBCxAQP2sgkACjw8PLEFBPWyAggLPDw8sQQE9bIGBwM8PDyxDQPmEwcFFzUnATUNARc3gQEBAP%2F%2FAQD%2FAP8AAf8Bq1aAgFaAASpWgIBWgAACAIAAVQKBAqsABQALAGwYsEEaALEAABMQsQAG5LEAARMQsAk8sQEF9bAKPLAAELEFA%2FWxAgXtsQQD9bEDBe2wChCxCwP1sQgF7bEGA%2FWxBwXtAbAMELEEA%2FayBwYDPDw8sQUE9bICCAs8PDyxAAT1sgkKATw8PLENA%2BYBFQ0BNSUBNQ0BFSUCgP8A%2FwABAP8AAQABAf7%2FAatWgIBWgAEqVoCAVoAAAQCAAVUC1QGrAAMAMBgBsAQQsQAD9rADPLECB%2FWwATyxBQPmALEAABMQsQAG5bEAARMQsAE8sQMF9bACPBMhFSGAAlX9qwGrVgABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAEA1IAVQMAAIADAACAA1YAgAAAAAAAAAAoAAAAzAAAAXIAAAG8AAEAAAAEAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2221%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2223.5%22%20y%3D%2221%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22math18ff5aca02e013ba3470d3c3575%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2216%22%3E%26lt%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2248.5%22%20y%3D%2216%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math18ff5aca02e013ba3470d3c3575%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2260.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math18ff5aca02e013ba3470d3c3575%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math18ff5aca02e013ba3470d3c3575%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2216%22%3E%26gt%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22112.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2216%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22157.5%22%20y%3D%2216%22%3E%26%23xE8%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22166.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22175.5%22%20y%3D%2216%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22181.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22187.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22199.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22203.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22209.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22218.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22227.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22234.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22245.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22254.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22263.5%22%20y%3D%2216%22%3Eg%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22272.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22279.5%22%20y%3D%2216%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22283.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22289.5%22%20y%3D%2216%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22297.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3C%2Fsvg%3E)
Si format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1b7337d4c93018f5f43793138a4'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAERjdnQgDVUNBwAAAWAAAAA6Z2x5ZoPi2VsAAAGcAAABomhlYWQQC2qxAAADQAAAADZoaGVhCGsXSAAAA3gAAAAkaG10eE2rRkcAAAOcAAAAEGxvY2EAHTwYAAADrAAAABRtYXhwBT0FPgAAA8AAAAAgbmFtZaBxlY4AAAPgAAABn3Bvc3QB9wD6AAAFgAAAACBwcmVwa1uragAABaAAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADAAAAAIAAgAAgAAAD0APiIS%2F%2F8AAAA9AD4iEv%2F%2F%2F8T%2FxN3xAAEAAAAAAAAAAAAAAVQDLACAAQAAVgAqAlgCHgEOASwCLABaAYACgACgANQAgAAAAAAAAAArAFUAgACrANUBAAErAAcAAAACAFUAAAMAA6sAAwAHAAAzESERJSERIVUCq%2F2rAgD%2BAAOr%2FFVVAwAAAgCAAOsC1QIVAAMABwBlGAGwCBCwBtSwBhCwBdSwCBCwAdSwARCwANSwBhCwBzywBRCwBDywARCwAjywABCwAzwAsAgQsAbUsAYQsAfUsAcQsAHUsAEQsALUsAYQsAU8sAcQsAQ8sAEQsAA8sAIQsAM8MTATITUhHQEhNYACVf2rAlUBwFXVVVUAAgCAAFUCgQKrAAUACwBsGLBBGgCxAAATELEABuSxAAETELAJPLEBBfWwCjywABCxBQP1sQIF7bEEA%2FWxAwXtsAoQsQsD9bEIBe2xBgP1sQcF7QGwDBCxBAP2sgcGAzw8PLEFBPWyAggLPDw8sQAE9bIJCgE8PDyxDQPmARUNATUlATUNARUlAoD%2FAP8AAQD%2FAAEAAQH%2B%2FwGrVoCAVoABKlaAgFaAAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAAABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAEA1IAVQNWAIADAACAA1YAgAAAAAAAAAAoAAAAsgAAAVgAAAGiAAEAAAAEAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2221%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2223.5%22%20y%3D%2221%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b7337d4c93018f5f43793138a4%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2216%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2249.5%22%20y%3D%2216%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b7337d4c93018f5f43793138a4%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b7337d4c93018f5f43793138a4%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2276.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1b7337d4c93018f5f43793138a4%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2216%22%3E%26gt%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22104.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22113.5%22%20y%3D%2216%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22127.5%22%20y%3D%2216%22%3Eh%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22134.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22145.5%22%20y%3D%2216%22%3Eh%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22154.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22168.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22177.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22186.5%22%20y%3D%2216%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22195.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22204.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22213.5%22%20y%3D%2216%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22222.5%22%20y%3D%2216%22%3E%26%23xE8%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22231.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22240.5%22%20y%3D%2216%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22246.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22252.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22264.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22268.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22274.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22283.5%22%20y%3D%2216%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22292.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22299.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3C%2Fsvg%3E)
Correlació
Coeficient de correlació
La correlació, que es calcula a partir de la covariància, a més de dir-nos si hi ha o no dependència de tipus lineal, ens dóna informació sobre el grau d'aquesta dependència. Ens diu si aquesta dependència és forta o fluixa.Si estudiem la correlació entre dues variables, podem mesurar-la quantitativament, mitjançant el coeficient de correlació lineal de Pearson r.
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%220.5%22%20y1%3D%220.5%22%20y2%3D%2252.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22113.5%22%20x2%3D%22113.5%22%20y1%3D%220.5%22%20y2%3D%2252.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22113.5%22%20y1%3D%220.5%22%20y2%3D%220.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22113.5%22%20y1%3D%2252.5%22%20y2%3D%2252.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2232%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2237%22%3EXY%3C%2Ftext%3E%3Ctext%20font-family%3D%22math164ced1e48f486e642fc427eb8a%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2239.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2250.5%22%20x2%3D%22104.5%22%20y1%3D%2226.5%22%20y2%3D%2226.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%2221%22%3EXY%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%2244%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2267.5%22%20y%3D%2249%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22math164ced1e48f486e642fc427eb8a%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2244%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2244%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2249%22%3EY%3C%2Ftext%3E%3C%2Fsvg%3E)
El coeficient de correlació és un nombre entre -1 i 1.
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22math1ca1a29523a31a98778ef30b146%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2217.5%22%20y%3D%2216%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1ca1a29523a31a98778ef30b146%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2230.5%22%20y%3D%2216%22%3E%26%23x2264%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%2216%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2248.5%22%20y%3D%2221%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2221%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1ca1a29523a31a98778ef30b146%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2216%22%3E%26%23x2264%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2281.5%22%20y%3D%2216%22%3E1%3C%2Ftext%3E%3C%2Fsvg%3E)
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math13f44cbd353f39abe56902119c1'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAGRjdnQgDVUNBwAAAYAAAAA6Z2x5ZoPi2VsAAAG8AAACXWhlYWQQC2qxAAAEHAAAADZoaGVhCGsXSAAABFQAAAAkaG10eE2rRkcAAAR4AAAAIGxvY2EAHTwYAAAEmAAAACRtYXhwBT0FPgAABLwAAAAgbmFtZaBxlY4AAATcAAABn3Bvc3QB9wD6AAAGfAAAACBwcmVwa1uragAABpwAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEAFAAAAAQABAAAwAAACcALAAuAD0AtyIRIhL%2F%2FwAAACcALAAuAD0AtyIRIhL%2F%2F%2F%2Fa%2F9b%2F1f%2FH%2F07d9d31AAEAAAAAAAAAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAFUB1QDVAysAAwAbGAGwBBCxAAX0sQED9LEFBfQAsAQQsQAC9DAxEzMDI1WAVioDK%2F6qAAEAVf9kANUAgAAKAAAzNTMVFAYHJz4BN1WALy8bHh4BgHo9URQpDjQxAAEAIAAAAKAAgAADAC8YAbAEELAD1LADELAC1LADELAAPLACELABPACwBBCwA9SwAxCwAjywABCwATwwMTczFSMggICAgAACAIAA6wLVAhUAAwAHAGUYAbAIELAG1LAGELAF1LAIELAB1LABELAA1LAGELAHPLAFELAEPLABELACPLAAELADPACwCBCwBtSwBhCwB9SwBxCwAdSwARCwAtSwBhCwBTywBxCwBDywARCwADywAhCwAzwxMBMhNSEdASE1gAJV%2FasCVQHAVdVVVQABAIABVQDrAcAAAwAbGAGwBBCxAAP0sQID9LEFA%2FQAsAQQsQMG9DAxEzMVI4BrawHAawABAIAAAAMrAysADwBKGAGwEBCxBAP2sAA8sQkD9bALPLEGC%2FWwDjyxEQPmsQcG%2FbANPACxBAA%2FsQgF%2FbEDCTw8sQYF7bEAAj%2BxDAX9sQsBPDyxDgX9MTATFQkBFSE1IxUhCQEhFTM1gAEr%2FtUCqyv%2BAAEr%2FtUCACsDK1X%2B%2F%2F6AVatWAYABAVarAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAAAAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAACANSAFUBKwBVATMAVQDIACADVgCAAWsAgAOsAIADVgCAAAAAAAAAACgAAABdAAAAhwAAAM0AAAFXAAABigAAAhMAAAJdAAEAAAAIAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2217.5%22%20y%3D%2221%22%3Exy%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%2216%22%3E%26%23xE9%3Bs%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2260.5%22%20y%3D%2216%22%3Ela%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22117.5%22%20y%3D%2216%22%3Ecovari%26%23xE0%3Bncia%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2276%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2216.5%22%20y%3D%2281%22%3Exy%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2230.5%22%20y%3D%2276%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2241.5%22%20x2%3D%22118.5%22%20y1%3D%2270.5%22%20y2%3D%2270.5%22%2F%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%2252%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2265%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%2265%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%2265%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2269.5%22%20y%3D%2249%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2254%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2280.5%22%20y%3D%2249%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2249%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2293.5%22%20y%3D%2254%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2299.5%22%20y%3D%2249%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22107.5%22%20y%3D%2249%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%2254%22%3Eij%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2280.5%22%20y%3D%2287%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22132.5%22%20y%3D%2276%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22144.5%22%20x2%3D%22151.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%2276%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22160.5%22%20y%3D%2276%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22168.5%22%20x2%3D%22175.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22172.5%22%20y%3D%2276%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22206.5%22%20y%3D%2276%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22221.5%22%20y%3D%2276%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22234.5%22%20y%3D%2276%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22245.5%22%20y%3D%2276%22%3E%26%23xBA%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22256.5%22%20y%3D%2276%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22262.5%22%20y%3D%2276%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22269.5%22%20y%3D%2276%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22275.5%22%20y%3D%2276%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22282.5%22%20y%3D%2276%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22293.5%22%20y%3D%2276%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22301.5%22%20y%3D%2276%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22306.5%22%20y%3D%2276%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22312.5%22%20y%3D%2276%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22321.5%22%20y%3D%2276%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22328.5%22%20y%3D%2276%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22334.5%22%20y%3D%2276%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22340.5%22%20y%3D%2276%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22346.5%22%20y%3D%2276%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22355.5%22%20y%3D%2276%22%3Eu%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22364.5%22%20y%3D%2276%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22377.5%22%20y%3D%2276%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22386.5%22%20y%3D%2276%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22392.5%22%20y%3D%2276%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22398.5%22%20y%3D%2276%22%3Eu%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22407.5%22%20y%3D%2276%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22414.5%22%20y%3D%2276%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22420.5%22%20y%3D%2276%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22427.5%22%20y%3D%2276%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22433.5%22%20y%3D%2276%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22440.5%22%20y%3D%2276%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22130%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%22135%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2232.5%22%20y%3D%22130%22%3E%26%23xE9%3Bs%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%22130%22%3Ela%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%22130%22%3Edesviaci%26%23xF3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22168.5%22%20y%3D%22130%22%3Et%26%23xED%3Bpica%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22200.5%22%20y%3D%22130%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22249.5%22%20y%3D%22130%22%3Eest%26%23xE0%3Bndard%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22304.5%22%20y%3D%22130%22%3Ede%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22326.5%22%20y%3D%22130%22%3Ela%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22369.5%22%20y%3D%22130%22%3Evariable%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22412.5%22%20y%3D%22130%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22193%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2213.5%22%20y%3D%22198%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2224.5%22%20y%3D%22193%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2212%2C-58%2011%2C-58%205%2C0%202%2C-23%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(33.5%2C205.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%225%2C0%202%2C-23%200%2C-20%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(33.5%2C205.5)%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2245.5%22%20x2%3D%22163.5%22%20y1%3D%22147.5%22%20y2%3D%22147.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2249.5%22%20x2%3D%22109.5%22%20y1%3D%22187.5%22%20y2%3D%22187.5%22%2F%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%22170%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%22182%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%22167%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2282.5%22%20y%3D%22174%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%22160%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%22167%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22100.5%22%20y%3D%22167%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%22172%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2280.5%22%20y%3D%22204%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%22193%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22135.5%22%20x2%3D%22142.5%22%20y1%3D%22177.5%22%20y2%3D%22177.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%22193%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%22186%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22247%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%22252%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2232.5%22%20y%3D%22247%22%3E%26%23xE9%3Bs%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%22247%22%3Ela%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%22247%22%3Edesviaci%26%23xF3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22168.5%22%20y%3D%22247%22%3Et%26%23xED%3Bpica%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22200.5%22%20y%3D%22247%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22249.5%22%20y%3D%22247%22%3Eest%26%23xE0%3Bndard%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22304.5%22%20y%3D%22247%22%3Ede%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22326.5%22%20y%3D%22247%22%3Ela%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22369.5%22%20y%3D%22247%22%3Evariable%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22412.5%22%20y%3D%22247%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22310%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2213.5%22%20y%3D%22315%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2224.5%22%20y%3D%22310%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2212%2C-58%2011%2C-58%205%2C0%202%2C-23%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(33.5%2C322.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%225%2C0%202%2C-23%200%2C-20%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(33.5%2C322.5)%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2245.5%22%20x2%3D%22163.5%22%20y1%3D%22264.5%22%20y2%3D%22264.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2249.5%22%20x2%3D%22109.5%22%20y1%3D%22304.5%22%20y2%3D%22304.5%22%2F%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%22287%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%22299%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%22284%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2282.5%22%20y%3D%22291%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%22277%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%22284%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%22284%22%3Enj%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2280.5%22%20y%3D%22321%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math13f44cbd353f39abe56902119c1%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%22310%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22135.5%22%20x2%3D%22142.5%22%20y1%3D%22294.5%22%20y2%3D%22294.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22139.5%22%20y%3D%22310%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%22303%22%3E2%3C%2Ftext%3E%3C%2Fsvg%3E)
Com interpretarem la correlació r?
-
- -1≤ r ≤ 1 sempre
- Si r > 0 (nombre positiu), hi ha correlació lineal positiva o directa
- Si r < 0 (nombre negatiu), hi ha correlació lineal negativa o inversa
- Si r = -1 Les dues variables estaran correlacionades linealment de forma perfecta, i el núvol de punts es disposa exactament damunt d'una línia recta decreixent (a la pràctica rarament serà així)
- Si r = 1 Les dues variables estaran correlacionades linealment de forma perfecte, i el núvol de punts es disposa exactament damunt d'una d'una línia recta creixent (a la pràctica rarament serà així)
- Com més proper sigui r a -1, la correlació serà més forta i inversa
- Com més proper sigui r a 1, la correlació serà més forta i directa
- Com més proper sigui r a 0, la correlació serà més dèbil, és a dir el núvol de punts s'assemblarà menys a la recta.
Gràficament :
|
|
|
|
correlació positiva o directa, dèbil |
correlació positiva o directa, forta |
|
|

|
|
correlació negativa o inversa, forta |
No hi ha correlació |



Com es calcula el coeficient de correlació?
El coeficient de Pearson, r, d'una
variable bidimensional (X,Y) és un paràmetre estadístic que es calcula a
partir de l'expressió:
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%230000FF%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%220.5%22%20y1%3D%220.5%22%20y2%3D%2252.5%22%2F%3E%3Cline%20stroke%3D%22%230000FF%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22107.5%22%20x2%3D%22107.5%22%20y1%3D%220.5%22%20y2%3D%2252.5%22%2F%3E%3Cline%20stroke%3D%22%230000FF%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22107.5%22%20y1%3D%220.5%22%20y2%3D%220.5%22%2F%3E%3Cline%20stroke%3D%22%230000FF%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%22107.5%22%20y1%3D%2252.5%22%20y2%3D%2252.5%22%2F%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2232%22%3Er%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22math164ced1e48f486e642fc427eb8a%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2227.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23191919%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2238.5%22%20x2%3D%2288.5%22%20y1%3D%2226.5%22%20y2%3D%2226.5%22%2F%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2221%22%3Ex%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2272.5%22%20y%3D%2221%22%3Ey%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2245.5%22%20y%3D%2244%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%2249%22%3Ex%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22math164ced1e48f486e642fc427eb8a%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%2244%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2244%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23191919%22%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%2249%22%3Ey%3C%2Ftext%3E%3C%2Fsvg%3E)
on
%3C%2Fmo%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmsub%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23x3C3%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold%22%3Ex%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xE9%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ec%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xF3%3B%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xED%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ep%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ec%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eo%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xE0%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3En%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eb%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3EX%3C%2Fmi%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmsub%3E%3Cmi%3E%26%23x3C3%3B%3C%2Fmi%3E%3Cmi%3Ex%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmsqrt%3E%3Cmfrac%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmunder%3E%3Cmsubsup%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsubsup%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmstyle%3E%3Cmi%3EN%3C%2Fmi%3E%3C%2Fmfrac%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E-%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmenclose%20notation%3D%22top%22%3E%3Cmi%3Ex%3C%2Fmi%3E%3C%2Fmenclose%3E%3Cmsup%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmsqrt%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmsub%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23x3C3%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold%22%3Ey%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xE9%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ec%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xF3%3B%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xED%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ep%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ec%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eo%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Es%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3E%26%23xE0%3B%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3En%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eb%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3EY%3C%2Fmi%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmsub%3E%3Cmi%3E%26%23x3C3%3B%3C%2Fmi%3E%3Cmi%3Ey%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmsqrt%3E%3Cmfrac%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmunder%3E%3Cmsubsup%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsubsup%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmstyle%3E%3Cmi%3EN%3C%2Fmi%3E%3C%2Fmfrac%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E-%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmenclose%20notation%3D%22top%22%3E%3Cmi%3Ey%3C%2Fmi%3E%3C%2Fmenclose%3E%3Cmsup%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmsqrt%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Em%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ej%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3En%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eb%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3EX%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%3A%3C%2Fmo%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmenclose%20notation%3D%22top%22%3E%3Cmi%3Ex%3C%2Fmi%3E%3C%2Fmenclose%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmfrac%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmunder%3E%3Cmsubsup%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3Cmrow%2F%3E%3C%2Fmsubsup%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmstyle%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmunder%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmstyle%3E%3C%2Fmfrac%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Em%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Et%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ej%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3En%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ed%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ev%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Er%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ei%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ea%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Eb%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3El%3C%2Fmi%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3Ee%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%20mathvariant%3D%22bold-italic%22%3EY%3C%2Fmi%3E%3Cmo%20mathvariant%3D%22bold%22%3E%3A%3C%2Fmo%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmenclose%20notation%3D%22top%22%3E%3Cmi%3Ey%3C%2Fmi%3E%3C%2Fmenclose%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmfrac%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmunder%3E%3Cmsubsup%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3Cmrow%2F%3E%3C%2Fmsubsup%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmstyle%3E%3Cmstyle%20displaystyle%3D%22true%22%3E%3Cmunder%3E%3Cmrow%3E%3Cmo%3E%26%23x2211%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmsub%3E%3C%2Fmrow%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmunder%3E%3C%2Fmstyle%3E%3C%2Fmfrac%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'ae2ef524fbf3d9fe611d5a8e90fefdc'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjv%2FLJYAAADMAAAATmNtYXDgWxEdAAABHAAAADRjdnQgAAAABwAAAVAAAAAEZ2x5ZoYrxVAAAAFUAAAA0WhlYWQOdyayAAACKAAAADZoaGVhC0UVwQAAAmAAAAAkaG10eCg8AIUAAAKEAAAACGxvY2EAAAVKAAACjAAAAAxtYXhwBIoEWwAAApgAAAAgbmFtZXSF9ZsAAAK4AAABrXBvc3QDogHPAAAEaAAAACBwcmVwukanGAAABIgAAAANAAAGtAGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAAGH%2F%2FwAAAGH%2F%2F%2F%2BgAAEAAAAAAAAABwACAFUAAAMAA6sAAwAHAAAzESERJSERIVUCq%2F2rAgD%2BAAOr%2FFVVAwAAAwAt%2F3QEAwRZAAsAFwAdADsYAbAdELAD1LADELAU1LAUELAc1LAcELAJ1LAcELAOPLAJELAbPACwBhCwEdSwBhCwANSwABCwF9QwMQEiABEWEjMyEjcQJgYWAwIGIyImNTQ2MwE1BhMjEgIBs%2F7fFvWy07oDhYZwFgxOhVmysoUB7YwEslEEWf7f%2Ft71%2Ft8BM%2BMBp5yyLf6d%2FwBlyJzfsvxZjF0B5%2F1eAAAAAAEAAAABAACav9usXw889QADCAD%2F%2F%2F%2F%2F1a3uPf%2F%2F%2F%2F%2FVre49AAH%2B9QQDBkMAAAAKAAIAAQAAAAAAAQAABz7%2BTgAAF3AAAf%2F8BAMAAQAAAAAAAAAAAAAAAAAAAAIDUgBVBEwALQAAAAAAAAAoAAAA0QABAAAAAgAeAAMAAAAAAAIAgAQAAAAAAAQAADsAAAAAAAAAFQECAAAAAAAAAAEAFgAAAAAAAAAAAAIADgAWAAAAAAAAAAMANAAkAAAAAAAAAAQAFgBYAAAAAAAAAAUAFgBuAAAAAAAAAAYACwCEAAAAAAAAAAgAHACPAAEAAAAAAAEAFgAAAAEAAAAAAAIADgAWAAEAAAAAAAMANAAkAAEAAAAAAAQAFgBYAAEAAAAAAAUAFgBuAAEAAAAAAAYACwCEAAEAAAAAAAgAHACPAAMAAQQJAAEAFgAAAAMAAQQJAAIADgAWAAMAAQQJAAMANAAkAAMAAQQJAAQAFgBYAAMAAQQJAAUAFgBuAAMAAQQJAAYACwCEAAMAAQQJAAgAHACPAE0AYQB0AGgAIABGAG8AbgB0ACAAMgBSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0ACAAMgBNAGEAdABoACAARgBvAG4AdAAgADIAVgBlAHIAcwBpAG8AbgAgADEALgAwTWF0aF9Gb250XzIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5ByIAAI2FGACyAAAAAAAA)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math11b9557ef652ac1a4d6bfc27b8b'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAFRjdnQgDVUNBwAAAXAAAAA6Z2x5ZoPi2VsAAAGsAAAB4mhlYWQQC2qxAAADkAAAADZoaGVhCGsXSAAAA8gAAAAkaG10eE2rRkcAAAPsAAAAGGxvY2EAHTwYAAAEBAAAABxtYXhwBT0FPgAABCAAAAAgbmFtZaBxlY4AAARAAAABn3Bvc3QB9wD6AAAF4AAAACBwcmVwa1uragAABgAAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEAEAAAAAMAAgAAgAEACwAPQC3IhEiEv%2F%2FAAAALAA9ALciESIS%2F%2F%2F%2F1f%2FF%2F0zd893zAAEAAAAAAAAAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAEAVf9kANUAgAAKAAAzNTMVFAYHJz4BN1WALy8bHh4BgHo9URQpDjQxAAIAgADrAtUCFQADAAcAZRgBsAgQsAbUsAYQsAXUsAgQsAHUsAEQsADUsAYQsAc8sAUQsAQ8sAEQsAI8sAAQsAM8ALAIELAG1LAGELAH1LAHELAB1LABELAC1LAGELAFPLAHELAEPLABELAAPLACELADPDEwEyE1IR0BITWAAlX9qwJVAcBV1VVVAAEAgAFVAOsBwAADABsYAbAEELEAA%2FSxAgP0sQUD9ACwBBCxAwb0MDETMxUjgGtrAcBrAAEAgAAAAysDKwAPAEoYAbAQELEEA%2FawADyxCQP1sAs8sQYL9bAOPLERA%2BaxBwb9sA08ALEEAD%2BxCAX9sQMJPDyxBgXtsQACP7EMBf2xCwE8PLEOBf0xMBMVCQEVITUjFSEJASEVMzWAASv%2B1QKrK%2F4AASv%2B1QIAKwMrVf7%2F%2FoBVq1YBgAEBVqsAAQCAAVUC1QGrAAMAMBgBsAQQsQAD9rADPLECB%2FWwATyxBQPmALEAABMQsQAG5bEAARMQsAE8sQMF9bACPBMhFSGAAlX9qwGrVgAAAAEAAAABAADVeM5BXw889QADBAD%2F%2F%2F%2F%2F1joTc%2F%2F%2F%2F%2F%2FWOhNzAAD%2FIASAA6sAAAAKAAIAAQAAAAAAAQAAA%2Bj%2FagAAF3AAAP%2B2BIAAAQAAAAAAAAAAAAAAAAAAAAYDUgBVATMAVQNWAIABawCAA6wAgANWAIAAAAAAAAAAKAAAAFIAAADcAAABDwAAAZgAAAHiAAEAAAAGAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2216%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2221%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2222.5%22%20y%3D%2221%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2216%22%3E%26%23xE9%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2245.5%22%20y%3D%2216%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2216%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2264.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%2216%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2289.5%22%20y%3D%2216%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2216%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22107.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22115.5%22%20y%3D%2216%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22120.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22127.5%22%20y%3D%2216%22%3E%26%23xE0%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22137.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22146.5%22%20y%3D%2216%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22153.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22159.5%22%20y%3D%2216%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2276%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%2281%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2220.5%22%20y%3D%2281%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2232.5%22%20y%3D%2276%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2243.5%22%20x2%3D%22127.5%22%20y1%3D%2270.5%22%20y2%3D%2270.5%22%2F%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2252%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%2265%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2265%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2265%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%2249%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2254%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2249%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2249%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2254%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22105.5%22%20y%3D%2249%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22113.5%22%20y%3D%2249%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22120.5%22%20y%3D%2254%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%2254%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%2287%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22141.5%22%20y%3D%2276%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22153.5%22%20x2%3D%22161.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22157.5%22%20y%3D%2276%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22170.5%22%20y%3D%2276%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22178.5%22%20x2%3D%22186.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22182.5%22%20y%3D%2276%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22214.5%22%20y%3D%2276%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22230.5%22%20y%3D%2276%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22245.5%22%20y%3D%2276%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%22265.5%22%20y%3D%2279%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22280.5%22%20y%3D%2276%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22286.5%22%20y%3D%2281%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22270.5%22%20y%3D%2295%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22297.5%22%20y%3D%2276%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%22317.5%22%20y%3D%2279%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22332.5%22%20y%3D%2276%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22338.5%22%20y%3D%2281%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22322.5%22%20y%3D%2297%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22355.5%22%20y%3D%2276%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22140%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%22145%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2229.5%22%20y%3D%22140%22%3E%26%23xE9%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%22140%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%22140%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%22140%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%22140%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%22140%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%22140%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22108.5%22%20y%3D%22140%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%22140%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%22140%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22137.5%22%20y%3D%22140%22%3E%26%23xF3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%22140%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%22140%22%3E%26%23xED%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22163.5%22%20y%3D%22140%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22170.5%22%20y%3D%22140%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22176.5%22%20y%3D%22140%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22185.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22201.5%22%20y%3D%22140%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22217.5%22%20y%3D%22140%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22226.5%22%20y%3D%22140%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22233.5%22%20y%3D%22140%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22241.5%22%20y%3D%22140%22%3E%26%23xE0%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22251.5%22%20y%3D%22140%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22261.5%22%20y%3D%22140%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22270.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22278.5%22%20y%3D%22140%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22286.5%22%20y%3D%22140%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22302.5%22%20y%3D%22140%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22312.5%22%20y%3D%22140%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22325.5%22%20y%3D%22140%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22331.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22346.5%22%20y%3D%22140%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22355.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22363.5%22%20y%3D%22140%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22368.5%22%20y%3D%22140%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22374.5%22%20y%3D%22140%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22384.5%22%20y%3D%22140%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22391.5%22%20y%3D%22140%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22398.5%22%20y%3D%22140%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22415.5%22%20y%3D%22140%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22203%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%22208%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%22203%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2212%2C-58%2011%2C-58%205%2C0%202%2C-23%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(35.5%2C215.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%225%2C0%202%2C-23%200%2C-20%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(35.5%2C215.5)%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2247.5%22%20x2%3D%22169.5%22%20y1%3D%22157.5%22%20y2%3D%22157.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2251.5%22%20x2%3D%22114.5%22%20y1%3D%22197.5%22%20y2%3D%22197.5%22%2F%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2264.5%22%20y%3D%22180%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%22192%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%22177%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%22184%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2287.5%22%20y%3D%22170%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%22177%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%22177%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%22182%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%22214%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22128.5%22%20y%3D%22203%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22140.5%22%20x2%3D%22148.5%22%20y1%3D%22187.5%22%20y2%3D%22187.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22144.5%22%20y%3D%22203%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22156.5%22%20y%3D%22196%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22257%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%22262%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2229.5%22%20y%3D%22257%22%3E%26%23xE9%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%22257%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%22257%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%22257%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%22257%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%22257%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%22257%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22108.5%22%20y%3D%22257%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%22257%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%22257%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22137.5%22%20y%3D%22257%22%3E%26%23xF3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22150.5%22%20y%3D%22257%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%22257%22%3E%26%23xED%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22163.5%22%20y%3D%22257%22%3Ep%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22170.5%22%20y%3D%22257%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22176.5%22%20y%3D%22257%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22185.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22201.5%22%20y%3D%22257%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22217.5%22%20y%3D%22257%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22226.5%22%20y%3D%22257%22%3Es%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22233.5%22%20y%3D%22257%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22241.5%22%20y%3D%22257%22%3E%26%23xE0%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22251.5%22%20y%3D%22257%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22261.5%22%20y%3D%22257%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22270.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22278.5%22%20y%3D%22257%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22286.5%22%20y%3D%22257%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22302.5%22%20y%3D%22257%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22312.5%22%20y%3D%22257%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22325.5%22%20y%3D%22257%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22331.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22346.5%22%20y%3D%22257%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22355.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22363.5%22%20y%3D%22257%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22368.5%22%20y%3D%22257%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22374.5%22%20y%3D%22257%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22384.5%22%20y%3D%22257%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22391.5%22%20y%3D%22257%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22398.5%22%20y%3D%22257%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22415.5%22%20y%3D%22257%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%22320%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%22325%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%22320%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2212%2C-58%2011%2C-58%205%2C0%202%2C-23%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(35.5%2C332.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%225%2C0%202%2C-23%200%2C-20%22%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(35.5%2C332.5)%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2247.5%22%20x2%3D%22169.5%22%20y1%3D%22274.5%22%20y2%3D%22274.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2251.5%22%20x2%3D%22114.5%22%20y1%3D%22314.5%22%20y2%3D%22314.5%22%2F%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2264.5%22%20y%3D%22297%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%22309%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%22294%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%22301%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2287.5%22%20y%3D%22287%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%22294%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%22294%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%22294%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%22331%22%3EN%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22128.5%22%20y%3D%22320%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22140.5%22%20x2%3D%22148.5%22%20y1%3D%22304.5%22%20y2%3D%22304.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22144.5%22%20y%3D%22320%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%22156.5%22%20y%3D%22313%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%227.5%22%20y%3D%22374%22%3Em%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2216.5%22%20y%3D%22374%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2220.5%22%20y%3D%22374%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2225.5%22%20y%3D%22374%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2231.5%22%20y%3D%22374%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2241.5%22%20y%3D%22374%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%22374%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2266.5%22%20y%3D%22374%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2276.5%22%20y%3D%22374%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2289.5%22%20y%3D%22374%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%22374%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%22374%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%22374%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22127.5%22%20y%3D%22374%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22132.5%22%20y%3D%22374%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22138.5%22%20y%3D%22374%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%22374%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%22374%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%22374%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22179.5%22%20y%3D%22374%22%3EX%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22188.5%22%20y%3D%22374%22%3E%3A%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%228.5%22%20y1%3D%22413.5%22%20y2%3D%22413.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%22429%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2217.5%22%20y%3D%22429%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2228.5%22%20x2%3D%2290.5%22%20y1%3D%22423.5%22%20y2%3D%22423.5%22%2F%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2241.5%22%20y%3D%22406%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%22418%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%22403%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%22410%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%22403%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%22403%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2286.5%22%20y%3D%22408%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%22448%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%22460%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2270.5%22%20y%3D%22445%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%22450%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%227.5%22%20y%3D%22503%22%3Em%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2216.5%22%20y%3D%22503%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2220.5%22%20y%3D%22503%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2225.5%22%20y%3D%22503%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2231.5%22%20y%3D%22503%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2241.5%22%20y%3D%22503%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%22503%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2266.5%22%20y%3D%22503%22%3Ed%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2276.5%22%20y%3D%22503%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2289.5%22%20y%3D%22503%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2295.5%22%20y%3D%22503%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22110.5%22%20y%3D%22503%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%22503%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22127.5%22%20y%3D%22503%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22132.5%22%20y%3D%22503%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22138.5%22%20y%3D%22503%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%22503%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%22503%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%22503%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22179.5%22%20y%3D%22503%22%3EY%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22188.5%22%20y%3D%22503%22%3E%3A%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%220.5%22%20x2%3D%228.5%22%20y1%3D%22542.5%22%20y2%3D%22542.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%22558%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%22558%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2232.5%22%20x2%3D%2294.5%22%20y1%3D%22552.5%22%20y2%3D%22552.5%22%2F%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2245.5%22%20y%3D%22535%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2244.5%22%20y%3D%22547%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2260.5%22%20y%3D%22532%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2266.5%22%20y%3D%22539%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%22532%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2283.5%22%20y%3D%22532%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2290.5%22%20y%3D%22537%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11b9557ef652ac1a4d6bfc27b8b%22%20font-size%3D%2224%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%22577%22%3E%26%23x2211%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2272.5%22%20y%3D%22574%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%22579%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2263.5%22%20y%3D%22593%22%3Ej%3C%2Ftext%3E%3C%2Fsvg%3E)
Procediment:
- Saber quina és la variable X, i quina és la variable Y
- Fem la taula de doble entrada
- A partir d'aquesta taula crearem 3 taules més:
- La primera d'aquestes taules serà de la variable X. En les columnes hi situarem els valors
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2218%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2223%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2219.5%22%20y%3D%2218%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2230.5%22%20y%3D%2218%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2223%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2218%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2223%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%2218%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2290.5%22%20y%3D%2218%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2296.5%22%20y%3D%2225%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2211%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2218%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2223%22%3Ei%3C%2Ftext%3E%3C%2Fsvg%3E)
- La segona d'aquestes taules serà de la variable Y. En les columnes hi situarem els valors
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2218%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2210.5%22%20y%3D%2223%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2219.5%22%20y%3D%2218%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2230.5%22%20y%3D%2218%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2223%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2218%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2251.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2223%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%2218%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2290.5%22%20y%3D%2218%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2296.5%22%20y%3D%2225%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2211%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2218%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2223%22%3Ej%3C%2Ftext%3E%3C%2Fsvg%3E)
- La tercera i última d'aquestes taules serà de la variable bidimensional XY. En les columnes hi situarem els valors
%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%2C%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmrow%3E%3Cmi%3Ei%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmrow%3E%3C%2Fmsub%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%3Ei%3C%2Fmi%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmi%3Ei%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmsub%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmsub%3E%3Cmi%3En%3C%2Fmi%3E%3Cmrow%3E%3Cmi%3Ei%3C%2Fmi%3E%3Cmi%3Ej%3C%2Fmi%3E%3C%2Fmrow%3E%3C%2Fmsub%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math16b4249fd15d33106a7bbeb51ae'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAAAhWhlYWQQC2qxAAACHAAAADZoaGVhCGsXSAAAAlQAAAAkaG10eE2rRkcAAAJ4AAAADGxvY2EAHTwYAAAChAAAABBtYXhwBT0FPgAAApQAAAAgbmFtZaBxlY4AAAK0AAABn3Bvc3QB9wD6AAAEVAAAACBwcmVwa1uragAABHQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACwAt%2F%2F%2FAAAALAC3%2F%2F%2F%2F1f9LAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAEAVf9kANUAgAAKAAAzNTMVFAYHJz4BN1WALy8bHh4BgHo9URQpDjQxAAEAgAFVAOsBwAADABsYAbAEELEAA%2FSxAgP0sQUD9ACwBBCxAwb0MDETMxUjgGtrAcBrAAAAAAEAAAABAADVeM5BXw889QADBAD%2F%2F%2F%2F%2F1joTc%2F%2F%2F%2F%2F%2FWOhNzAAD%2FIASAA6sAAAAKAAIAAQAAAAAAAQAAA%2Bj%2FagAAF3AAAP%2B2BIAAAQAAAAAAAAAAAAAAAAAAAAMDUgBVATMAVQFrAIAAAAAAAAAAKAAAAFIAAACFAAEAAAADAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%223.5%22%20y%3D%2216%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%229.5%22%20y%3D%2216%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2220.5%22%20y%3D%2216%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2227.5%22%20y%3D%2216%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2233.5%22%20y%3D%2221%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%2216%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2247.5%22%20y%3D%2216%22%3E%2C%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2268.5%22%20y%3D%2221%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2281.5%22%20y%3D%2216%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22100.5%22%20y%3D%2216%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22113.5%22%20y%3D%2216%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2216%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22127.5%22%20y%3D%2221%22%3Ej%3C%2Ftext%3E%3Ctext%20font-family%3D%22math16b4249fd15d33106a7bbeb51ae%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22134.5%22%20y%3D%2216%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22142.5%22%20y%3D%2216%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22149.5%22%20y%3D%2221%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22152.5%22%20y%3D%2221%22%3Ej%3C%2Ftext%3E%3C%2Fsvg%3E)
- La primera d'aquestes taules serà de la variable X. En les columnes hi situarem els valors
Amb aquestes tres taules i la suma total de les seves columnes, podreu calcular tots els paràmetres:
- Mitjana, variància i desviació estàndard (o típica) de X
- Mitjana, variància i desviació estàndard (o típica) de Y
- Covariància
- Coeficient de correlació lineal de Pearson
Encara que són molts passos, sempre són els mateixos. I per tant si sabeu fer un problema d'aquest tipus, segur que sabreu fer-los tots.
Exemple :
S'ha realitzat una enquesta a 50 persones preguntant per el nombre de persones (X) que habiten la llar familiar i el nombre d'habitacions (Y) que té la casa. Els resultats obtinguts (xi ,yj) són els següents:
(3,4),(2,1),(2,4),(3,2),(3,2),(3,3),(2,1),(2,2),(2,2),(4,5),
(4,3),(2,2),(5,4),(4,3),(4,2),(4,3),(4,3),(3,2),(3,4),(4,4),
(5,4),(6,4),(3,2),(2,2),(2,2),(4,5),(4,3),(2,3),(3,3),(3,4),
(3,2),(5,3),(6,5),(6,4),(2,2),(5,4),(4,3),(4,2),(4,3),(4,3),
(1,1),(2,4),(3,2),(3,2),(1,2),(4,3),(4,4),(1,2),(4,5),(3,3)
La taula de doble entrada següent mostra la distribució de dades obtingudes

També podem considerar les variables X i Y com a variables unidimensionals si volem trobar els seus paràmetres estadístics com ara la mitjana i la desviació tipus. Aquestes variables es coneixen com a marginals. Observem que a partir de la informació
bidimensional, sempre podem trobar les característiques de les variables marginals (X i Y pensades separadament), només s'han de sumar files o columnes segons el cas. Un cop tenim les marginals, ja podem calcular-ne tots els paràmetres estadístics
unidimensionals que ens calguin.


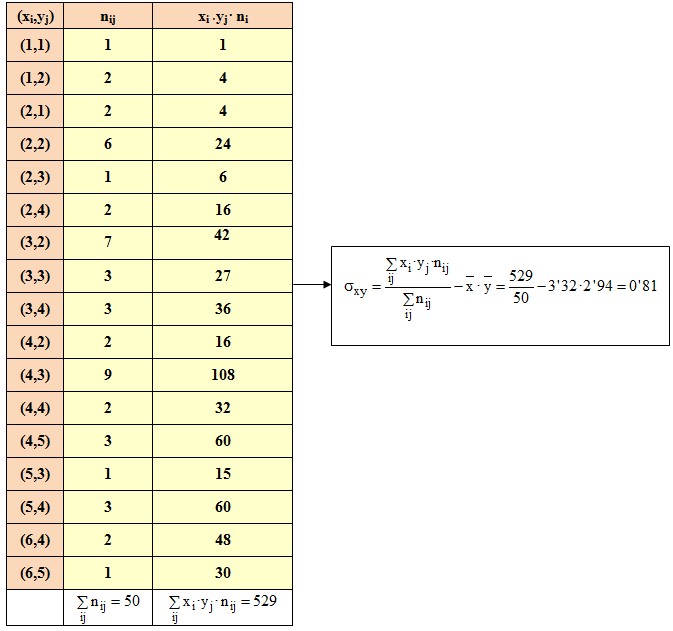
I ara finalment ja podem trobar el coeficient de Pearson: format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%222.5%22%20y%3D%2227%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2225.5%22%20x2%3D%22108.5%22%20y1%3D%2221.5%22%20y2%3D%2221.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2255.5%22%20y%3D%2216%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2262.5%22%20y%3D%2216%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2216%22%3E81%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2231.5%22%20y%3D%2239%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%2239%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2239%22%3E24%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2267.5%22%20y%3D%2239%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%2239%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2286.5%22%20y%3D%2239%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2298.5%22%20y%3D%2239%22%3E07%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22132.5%22%20x2%3D%22132.5%22%20y1%3D%2210.5%22%20y2%3D%2230.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22175.5%22%20x2%3D%22175.5%22%20y1%3D%2210.5%22%20y2%3D%2230.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22132.5%22%20x2%3D%22175.5%22%20y1%3D%2210.5%22%20y2%3D%2210.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22132.5%22%20x2%3D%22175.5%22%20y1%3D%2230.5%22%20y2%3D%2230.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22142.5%22%20y%3D%2227%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math180cdfd366586533d5b6bce9266%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22149.5%22%20y%3D%2227%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%22161.5%22%20y%3D%2227%22%3E61%3C%2Ftext%3E%3C%2Fsvg%3E)
A partir d'aquest valor que podríem dir? Doncs que hi ha certa dependència lineal positiva entre les dues variable, en prendre el valor 0,61 veiem que la dependència és forta però tampoc massa.
Recta de regressió
En una distribució bidimensional, una vegada constatada la correlació lineal entre les dues variables, mitjançant el coeficient de correlació lineal de Pearson (r) es poden fer estimacions, és a dir prediccions de valors possibles d'una variable.
Per fer aquestes prediccions, s'ha de calcular una recta de regressió, és a dir s'ha de buscar l'expressió algebraica de la recta que aproxima millor el núvol de punts.
Hi ha dues rectes de regressió que es calcularan en funció de la correlació i les mitjanes i variàncies de les variables marginals:
| La de Y sobre X | %3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmstyle%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math1a60847c1a62ffc0288bcc8a524'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAExjdnQgDVUNBwAAAWgAAAA6Z2x5ZoPi2VsAAAGkAAABqGhlYWQQC2qxAAADTAAAADZoaGVhCGsXSAAAA4QAAAAkaG10eE2rRkcAAAOoAAAAFGxvY2EAHTwYAAADvAAAABhtYXhwBT0FPgAAA9QAAAAgbmFtZaBxlY4AAAP0AAABn3Bvc3QB9wD6AAAFlAAAACBwcmVwa1uragAABbQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADgAAAAKAAgAAgACACsAPQC3IhL%2F%2FwAAACsAPQC3IhL%2F%2F%2F%2FW%2F8X%2FTN3yAAEAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAIAAVQLVAqsACwBJARiyDAEBFBMQsQAD9rEBBPWwCjyxAwX1sAg8sQUE9bAGPLENA%2BYAsQAAExCxAQbksQEBExCwBTyxAwTlsQsF9bAHPLEJBOUxMBMhETMRIRUhESMRIYABAFUBAP8AVf8AAasBAP8AVv8AAQAAAgCAAOsC1QIVAAMABwBlGAGwCBCwBtSwBhCwBdSwCBCwAdSwARCwANSwBhCwBzywBRCwBDywARCwAjywABCwAzwAsAgQsAbUsAYQsAfUsAcQsAHUsAEQsALUsAYQsAU8sAcQsAQ8sAEQsAA8sAIQsAM8MTATITUhHQEhNYACVf2rAlUBwFXVVVUAAQCAAVUA6wHAAAMAGxgBsAQQsQAD9LECA%2FSxBQP0ALAEELEDBvQwMRMzFSOAa2sBwGsAAQCAAVUC1QGrAAMAMBgBsAQQsQAD9rADPLECB%2FWwATyxBQPmALEAABMQsQAG5bEAARMQsAE8sQMF9bACPBMhFSGAAlX9qwGrVgABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAFA1IAVQNWAIADVgCAAWsAgANWAIAAAAAAAAAAKAAAAKEAAAErAAABXgAAAagAAQAAAAUAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2219.5%22%20y%3D%2234%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2239.5%22%20y%3D%2234%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2249.5%22%20x2%3D%2258.5%22%20y1%3D%2216.5%22%20y2%3D%2216.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2253.5%22%20y%3D%2234%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%2234%22%3E%2B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2285.5%22%20x2%3D%22115.5%22%20y1%3D%2227.5%22%20y2%3D%2227.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2217%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%2222%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22109.5%22%20y%3D%2222%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2296.5%22%20y%3D%2248%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2255%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2241%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22123.5%22%20y%3D%2234%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22131.5%22%20y%3D%2234%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22138.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22153.5%22%20y%3D%2234%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22163.5%22%20x2%3D%22172.5%22%20y1%3D%2216.5%22%20y2%3D%2216.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22167.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22175.5%22%20y%3D%2234%22%3E)%3C%2Ftext%3E%3C%2Fsvg%3E)
|
| La de X sobre Y | %3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmstyle%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math1a60847c1a62ffc0288bcc8a524'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAExjdnQgDVUNBwAAAWgAAAA6Z2x5ZoPi2VsAAAGkAAABqGhlYWQQC2qxAAADTAAAADZoaGVhCGsXSAAAA4QAAAAkaG10eE2rRkcAAAOoAAAAFGxvY2EAHTwYAAADvAAAABhtYXhwBT0FPgAAA9QAAAAgbmFtZaBxlY4AAAP0AAABn3Bvc3QB9wD6AAAFlAAAACBwcmVwa1uragAABbQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADgAAAAKAAgAAgACACsAPQC3IhL%2F%2FwAAACsAPQC3IhL%2F%2F%2F%2FW%2F8X%2FTN3yAAEAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAIAAVQLVAqsACwBJARiyDAEBFBMQsQAD9rEBBPWwCjyxAwX1sAg8sQUE9bAGPLENA%2BYAsQAAExCxAQbksQEBExCwBTyxAwTlsQsF9bAHPLEJBOUxMBMhETMRIRUhESMRIYABAFUBAP8AVf8AAasBAP8AVv8AAQAAAgCAAOsC1QIVAAMABwBlGAGwCBCwBtSwBhCwBdSwCBCwAdSwARCwANSwBhCwBzywBRCwBDywARCwAjywABCwAzwAsAgQsAbUsAYQsAfUsAcQsAHUsAEQsALUsAYQsAU8sAcQsAQ8sAEQsAA8sAIQsAM8MTATITUhHQEhNYACVf2rAlUBwFXVVVUAAQCAAVUA6wHAAAMAGxgBsAQQsQAD9LECA%2FSxBQP0ALAEELEDBvQwMRMzFSOAa2sBwGsAAQCAAVUC1QGrAAMAMBgBsAQQsQAD9rADPLECB%2FWwATyxBQPmALEAABMQsQAG5bEAARMQsAE8sQMF9bACPBMhFSGAAlX9qwGrVgABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAFA1IAVQNWAIADVgCAAWsAgANWAIAAAAAAAAAAKAAAAKEAAAErAAABXgAAAagAAQAAAAUAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2214.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2234%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2244.5%22%20x2%3D%2258.5%22%20y1%3D%2215.5%22%20y2%3D%2215.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2248.5%22%20y%3D%2234%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2268.5%22%20y%3D%2234%22%3E%2B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2280.5%22%20x2%3D%22110.5%22%20y1%3D%2227.5%22%20y2%3D%2227.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2287.5%22%20y%3D%2217%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2297.5%22%20y%3D%2222%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22104.5%22%20y%3D%2222%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2248%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%2255%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2213%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%2241%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22118.5%22%20y%3D%2234%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22126.5%22%20y%3D%2234%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22133.5%22%20y%3D%2234%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1a60847c1a62ffc0288bcc8a524%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22148.5%22%20y%3D%2234%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22158.5%22%20x2%3D%22167.5%22%20y1%3D%2216.5%22%20y2%3D%2216.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2218%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%2234%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22170.5%22%20y%3D%2234%22%3E)%3C%2Ftext%3E%3C%2Fsvg%3E)
|
La utilització d'una o l'altra depèn del context del problema. En ocasions l'enunciat ja diu quina recta utilitzar. En altres ocasions cal deduir-ho en funció de les dades.
Si es demana predir un valor de y donat el valor de x, cal usar la recta de Y sobre X, ja que és la recta en la que queda aïllada la Y.
Si es demana predir el valor de x coneixent la y corresponent, cal usar la recta de regressió de X sobre Y, ja que és la recta en la que queda aïllada la X.
La recta de regressió correspon a la recta que millor s'ajusta a la distribució de punts (núvol de punts).
Per exemple en la distribució bidimensional d'aquest notes:
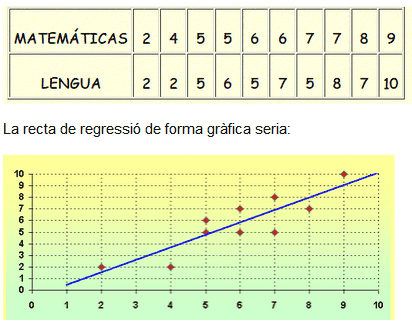
Procediment pel càlcul de la recta
- Saber quina és la variable X, i quina és la variable Y
- Fer una taula amb les columnes: valors de X, valors de Y , valors de X², valors de Y², valors de XY i els totals.
Amb aquestes columnes i la suma total d'aquestes columnes, es podran calcular tots els paràmetres:
- Mitjana, variància i desviació estàndard (o típica) de X
- Mitjana, variància i desviació estàndard (o típica) de Y
- Covariància
- Coeficient de correlació lineal de Pearson
- Recta de regressió de Y sobre X o bé Recta de regressió de X sobre Y
- Fer una predicció
Encara que són molts passos, sempre són els mateixos. I per tant si sabeu fer un problema d'aquest tipus, segur que sabreu fer-los tots.
Exemple
En la taula següent es donen les notes del test de aptitud (X) de sis aspirants a venedors i Y vendes realitzades per cada un, durant el primer mes, en cents d'euros.

a) Calcular "r" i interpretar el resultat
b) Trobar la recta de regressió de Y sobre X. Predir les vendes d'un venedor que tingui 47 en el test.
Resolució:



Observem que "r" és molt proper a 1, per tant la correlació lineal és forta i directa. A més nota en el test, més vendes és possible que faci l'aspirant.
r ens indica que les dues variables estan fortament relaciones, i per tant la predicció que ha sortit aplicant la recta de regressió, és fiable.
Després dels càlculs hem arribat a la conclusió que un aspirant amb 47 punts en el test, és probable que vengui per un valor de 76,41 cents d'euros = 7641 €
Exemple de regressió II
Seguint amb l'exemple treballat en el punt 2.4 on s'estudiaven les variables X= nombre d'habitants en una llar, Y=nombre d'habitacions.
En el punt 2.4 estaven fets els càlculs fins a trobar el coeficient de correlació de Pearson. Ara anem ara a cercar-ne la recta de regressió de Y sobre X.
%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmspace%20linebreak%3D%22newline%22%2F%3E%3Cmrow%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmn%3E2%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E94%3C%2Fmn%3E%3Cmo%3E%2B%3C%2Fmo%3E%3Cmfrac%3E%3Cmrow%3E%3Cmn%3E0%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E81%3C%2Fmn%3E%3C%2Fmrow%3E%3Cmrow%3E%3Cmn%3E1%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmsup%3E%3Cmn%3E24%3C%2Fmn%3E%3Cmn%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3C%2Fmrow%3E%3C%2Fmfrac%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmo%3E(%3C%2Fmo%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmo%3E-%3C%2Fmo%3E%3Cmn%3E3%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E32%3C%2Fmn%3E%3Cmo%3E)%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23x2192%3B%3C%2Fmo%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmn%3E2%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E94%3C%2Fmn%3E%3Cmo%3E%2B%3C%2Fmo%3E%3Cmn%3E0%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E53%3C%2Fmn%3E%3Cmo%3E%26%23xB7%3B%3C%2Fmo%3E%3Cmo%3E(%3C%2Fmo%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmo%3E-%3C%2Fmo%3E%3Cmn%3E3%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E32%3C%2Fmn%3E%3Cmo%3E)%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%26%23x2192%3B%3C%2Fmo%3E%3Cmenclose%20notation%3D%22box%22%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmi%3Ey%3C%2Fmi%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%3D%3C%2Fmo%3E%3Cmn%3E0%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E53%3C%2Fmn%3E%3Cmi%3Ex%3C%2Fmi%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%3E%2B%3C%2Fmo%3E%3Cmn%3E1%3C%2Fmn%3E%3Cmo%3E'%3C%2Fmo%3E%3Cmn%3E18%3C%2Fmn%3E%3Cmo%3E%26%23xA0%3B%3C%2Fmo%3E%3C%2Fmenclose%3E%3C%2Fmstyle%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math160004ecd399e4819d9ee0f4ea7'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAFxjdnQgDVUNBwAAAXgAAAA6Z2x5ZoPi2VsAAAG0AAACJmhlYWQQC2qxAAAD3AAAADZoaGVhCGsXSAAABBQAAAAkaG10eE2rRkcAAAQ4AAAAHGxvY2EAHTwYAAAEVAAAACBtYXhwBT0FPgAABHQAAAAgbmFtZaBxlY4AAASUAAABn3Bvc3QB9wD6AAAGNAAAACBwcmVwa1uragAABlQAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEAEgAAAAOAAgAAgAGACcAKwA9ALchkiIS%2F%2F8AAAAnACsAPQC3IZIiEv%2F%2F%2F9r%2F1%2F%2FG%2F03ec930AAEAAAAAAAAAAAAAAAAAAAAAAVQDLACAAQAAVgAqAlgCHgEOASwCLABaAYACgACgANQAgAAAAAAAAAArAFUAgACrANUBAAErAAcAAAACAFUAAAMAA6sAAwAHAAAzESERJSERIVUCq%2F2rAgD%2BAAOr%2FFVVAwAAAQBVAdUA1QMrAAMAGxgBsAQQsQAF9LEBA%2FSxBQX0ALAEELEAAvQwMRMzAyNVgFYqAyv%2BqgABAIAAVQLVAqsACwBJARiyDAEBFBMQsQAD9rEBBPWwCjyxAwX1sAg8sQUE9bAGPLENA%2BYAsQAAExCxAQbksQEBExCwBTyxAwTlsQsF9bAHPLEJBOUxMBMhETMRIRUhESMRIYABAFUBAP8AVf8AAasBAP8AVv8AAQAAAgCAAOsC1QIVAAMABwBlGAGwCBCwBtSwBhCwBdSwCBCwAdSwARCwANSwBhCwBzywBRCwBDywARCwAjywABCwAzwAsAgQsAbUsAYQsAfUsAcQsAHUsAEQsALUsAYQsAU8sAcQsAQ8sAEQsAA8sAIQsAM8MTATITUhHQEhNYACVf2rAlUBwFXVVVUAAQCAAVUA6wHAAAMAGxgBsAQQsQAD9LECA%2FSxBQP0ALAEELEDBvQwMRMzFSOAa2sBwGsAAQCAAKoDgAJVAAgAHwCxAAATELEABuWxAAETELABPLEDD%2BWxBwX1sQUP9TATISc1DQE1NyGAAitWASv%2B1Vb91QGqQWrV1mtAAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAAABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAHA1IAVQErAFUDVgCAA1YAgAFrAIAEAACAA1YAgAAAAAAAAAAoAAAAXQAAANYAAAFgAAABkwAAAdwAAAImAAEAAAAHAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2227%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2232.5%22%20y%3D%2227%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2240.5%22%20x2%3D%2247.5%22%20y1%3D%2213.5%22%20y2%3D%2213.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2243.5%22%20y%3D%2227%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2259.5%22%20y%3D%2227%22%3E%2B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2268.5%22%20x2%3D%2290.5%22%20y1%3D%2222.5%22%20y2%3D%2222.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%2213%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2210%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2281.5%22%20y%3D%2217%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2210%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2286.5%22%20y%3D%2217%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2276.5%22%20y%3D%2239%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2210%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2244%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2210%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%2233%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2296.5%22%20y%3D%2227%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22103.5%22%20y%3D%2227%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22108.5%22%20y%3D%2227%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22120.5%22%20y%3D%2227%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22127.5%22%20x2%3D%22134.5%22%20y1%3D%2213.5%22%20y2%3D%2213.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%2227%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22137.5%22%20y%3D%2227%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2275%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2228.5%22%20y%3D%2275%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%2275%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2246.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2275%22%3E94%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2271.5%22%20y%3D%2275%22%3E%2B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2280.5%22%20x2%3D%22115.5%22%20y1%3D%2270.5%22%20y2%3D%2270.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2265%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2294.5%22%20y%3D%2265%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22104.5%22%20y%3D%2265%22%3E81%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2285.5%22%20y%3D%2287%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2291.5%22%20y%3D%2287%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%2287%22%3E24%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2210%22%20text-anchor%3D%22middle%22%20x%3D%22112.5%22%20y%3D%2281%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22121.5%22%20y%3D%2275%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22128.5%22%20y%3D%2275%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22133.5%22%20y%3D%2275%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22145.5%22%20y%3D%2275%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22156.5%22%20y%3D%2275%22%3E3%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22172.5%22%20y%3D%2275%22%3E32%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22182.5%22%20y%3D%2275%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22206.5%22%20y%3D%2275%22%3E%26%23x2192%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22218.5%22%20y%3D%2275%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22235.5%22%20y%3D%2275%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22247.5%22%20y%3D%2275%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22253.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22263.5%22%20y%3D%2275%22%3E94%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22278.5%22%20y%3D%2275%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22289.5%22%20y%3D%2275%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22295.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22305.5%22%20y%3D%2275%22%3E53%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22316.5%22%20y%3D%2275%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22323.5%22%20y%3D%2275%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22328.5%22%20y%3D%2275%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22340.5%22%20y%3D%2275%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22351.5%22%20y%3D%2275%22%3E3%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22357.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22367.5%22%20y%3D%2275%22%3E32%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22377.5%22%20y%3D%2275%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22401.5%22%20y%3D%2275%22%3E%26%23x2192%3B%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22410.5%22%20x2%3D%22410.5%22%20y1%3D%2260.5%22%20y2%3D%2278.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22531.5%22%20x2%3D%22531.5%22%20y1%3D%2260.5%22%20y2%3D%2278.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22410.5%22%20x2%3D%22531.5%22%20y1%3D%2260.5%22%20y2%3D%2260.5%22%2F%3E%3Cline%20stroke%3D%22%23000000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22410.5%22%20x2%3D%22531.5%22%20y1%3D%2278.5%22%20y2%3D%2278.5%22%2F%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22419.5%22%20y%3D%2275%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22436.5%22%20y%3D%2275%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22448.5%22%20y%3D%2275%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22454.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22464.5%22%20y%3D%2275%22%3E53%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22475.5%22%20y%3D%2275%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22491.5%22%20y%3D%2275%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22502.5%22%20y%3D%2275%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math160004ecd399e4819d9ee0f4ea7%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22508.5%22%20y%3D%2275%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22518.5%22%20y%3D%2275%22%3E18%3C%2Ftext%3E%3C%2Fsvg%3E)
Si volem ara per exemple inferir quantes habitacions tindrà una llar on hi visquin 4 persones sols hem de substituir la x per 4
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math11f39b60019fecf88bff68ce652'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAFRjdnQgDVUNBwAAAXAAAAA6Z2x5ZoPi2VsAAAGsAAAB3GhlYWQQC2qxAAADiAAAADZoaGVhCGsXSAAAA8AAAAAkaG10eE2rRkcAAAPkAAAAGGxvY2EAHTwYAAAD%2FAAAABxtYXhwBT0FPgAABBgAAAAgbmFtZaBxlY4AAAQ4AAABn3Bvc3QB9wD6AAAF2AAAACBwcmVwa1uragAABfgAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEAEAAAAAMAAgAAgAEACcAKwA9ALchkv%2F%2FAAAAJwArAD0AtyGS%2F%2F%2F%2F2v%2FX%2F8b%2FTd5zAAEAAAAAAAAAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAEAVQHVANUDKwADABsYAbAEELEABfSxAQP0sQUF9ACwBBCxAAL0MDETMwMjVYBWKgMr%2FqoAAQCAAFUC1QKrAAsASQEYsgwBARQTELEAA%2FaxAQT1sAo8sQMF9bAIPLEFBPWwBjyxDQPmALEAABMQsQEG5LEBARMQsAU8sQME5bELBfWwBzyxCQTlMTATIREzESEVIREjESGAAQBVAQD%2FAFX%2FAAGrAQD%2FAFb%2FAAEAAAIAgADrAtUCFQADAAcAZRgBsAgQsAbUsAYQsAXUsAgQsAHUsAEQsADUsAYQsAc8sAUQsAQ8sAEQsAI8sAAQsAM8ALAIELAG1LAGELAH1LAHELAB1LABELAC1LAGELAFPLAHELAEPLABELAAPLACELADPDEwEyE1IR0BITWAAlX9qwJVAcBV1VVVAAEAgAFVAOsBwAADABsYAbAEELEAA%2FSxAgP0sQUD9ACwBBCxAwb0MDETMxUjgGtrAcBrAAEAgACqA4ACVQAIAB8AsQAAExCxAAblsQABExCwATyxAw%2FlsQcF9bEFD%2FUwEyEnNQ0BNTchgAIrVgEr%2FtVW%2FdUBqkFq1dZrQAABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAGA1IAVQErAFUDVgCAA1YAgAFrAIAEAACAAAAAAAAAACgAAABdAAAA1gAAAWAAAAGTAAAB3AABAAAABgBeAAUAAAAAAAIAgAQAAAAAAAQAAN4AAAAAAAAAFQECAAAAAAAAAAEAEgAAAAAAAAAAAAIADgASAAAAAAAAAAMAMAAgAAAAAAAAAAQAEgBQAAAAAAAAAAUAFgBiAAAAAAAAAAYACQB4AAAAAAAAAAgAHACBAAEAAAAAAAEAEgAAAAEAAAAAAAIADgASAAEAAAAAAAMAMAAgAAEAAAAAAAQAEgBQAAEAAAAAAAUAFgBiAAEAAAAAAAYACQB4AAEAAAAAAAgAHACBAAMAAQQJAAEAEgAAAAMAAQQJAAIADgASAAMAAQQJAAMAMAAgAAMAAQQJAAQAEgBQAAMAAQQJAAUAFgBiAAMAAQQJAAYACQB4AAMAAQQJAAgAHACBAE0AYQB0AGgAIABGAG8AbgB0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAATQBhAHQAaAAgAEYAbwBuAHQATQBhAHQAaAAgAEYAbwBuAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwTWF0aF9Gb250AE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAAAwAAAAAAAAH0APoAAAAAAAAAAAAAAAAAAAAAAAAAALkHEQAAjYUYALIAAAAVFBOxAAE%2F)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2214%22%3Ey%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2228.5%22%20y%3D%2214%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%2214%22%3E0%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2246.5%22%20y%3D%2214%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2256.5%22%20y%3D%2214%22%3E53%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2267.5%22%20y%3D%2214%22%3E%26%23xB7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%2214%22%3E4%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%2290.5%22%20y%3D%2214%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%2214%22%3E1%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22107.5%22%20y%3D%2214%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22117.5%22%20y%3D%2214%22%3E18%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22133.5%22%20y%3D%2214%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22149.5%22%20y%3D%2214%22%3E3%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%2214%22%3E'%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22161.5%22%20y%3D%2214%22%3E3%3C%2Ftext%3E%3Ctext%20font-family%3D%22math11f39b60019fecf88bff68ce652%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22186.5%22%20y%3D%2214%22%3E%26%23x2192%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20text-anchor%3D%22middle%22%20x%3D%22203.5%22%20y%3D%2214%22%3E3%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22215.5%22%20y%3D%2214%22%3Eh%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22223.5%22%20y%3D%2214%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22231.5%22%20y%3D%2214%22%3Eb%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22236.5%22%20y%3D%2214%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22240.5%22%20y%3D%2214%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22ae2ef524fbf3d9fe611d5a8e90fefdc%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22246.5%22%20y%3D%2214%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22253.5%22%20y%3D%2214%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22258.5%22%20y%3D%2214%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22264.5%22%20y%3D%2214%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22272.5%22%20y%3D%2214%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Arial%22%20font-size%3D%2214%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22279.5%22%20y%3D%2214%22%3Es%3C%2Ftext%3E%3C%2Fsvg%3E)
Si fem el núvol de punts o diagrama de dispersió consistent de tots els parells de valors que apareguin en la mostra i també hi dibuixem la recta de regressió tindrem: